World Labs Releases Three Foundational Papers on Spatial Intelligence
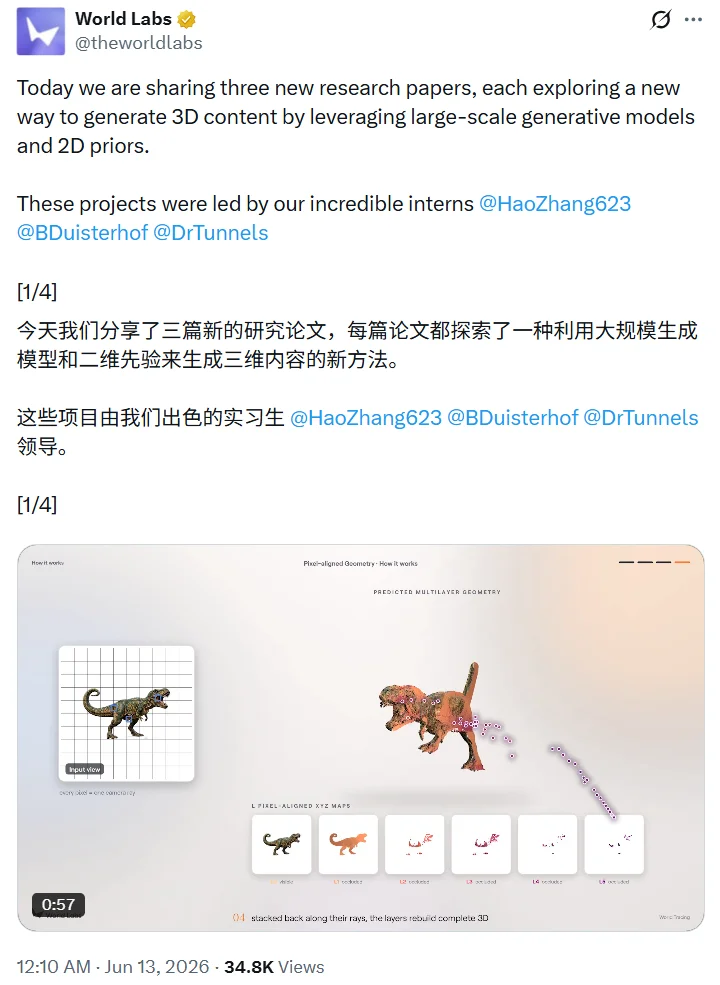
Today, World Labs — the spatial intelligence company co-founded by Dr. Fei-Fei Li — unveiled three technical papers on the same day. All three were led by internal interns and converge on a shared vision: leveraging mature 2D generative models trained on massive image datasets to dramatically lower the barrier for high-fidelity 3D content generation.
This marks World Labs’ first-ever academic publication release, as confirmed by co-founder Justin Johnson.

Why 3D Generation Remains Hard — And Why This Shift Matters
The real world is inherently 3D — yet most training data (photos, videos, web images) is 2D. Depth, occlusion, volumetric structure, and geometric consistency are absent in flat pixels. Transitioning to 3D introduces exponential complexity: scarce ground-truth 3D supervision, ambiguous inverse projections, and brittle geometry optimization.
For years, researchers have pursued a pragmatic path: transfer priors from powerful 2D diffusion models into 3D tasks — rather than training monolithic 3D generators from scratch. World Labs’ trio of papers advances this paradigm across distinct yet complementary axes.
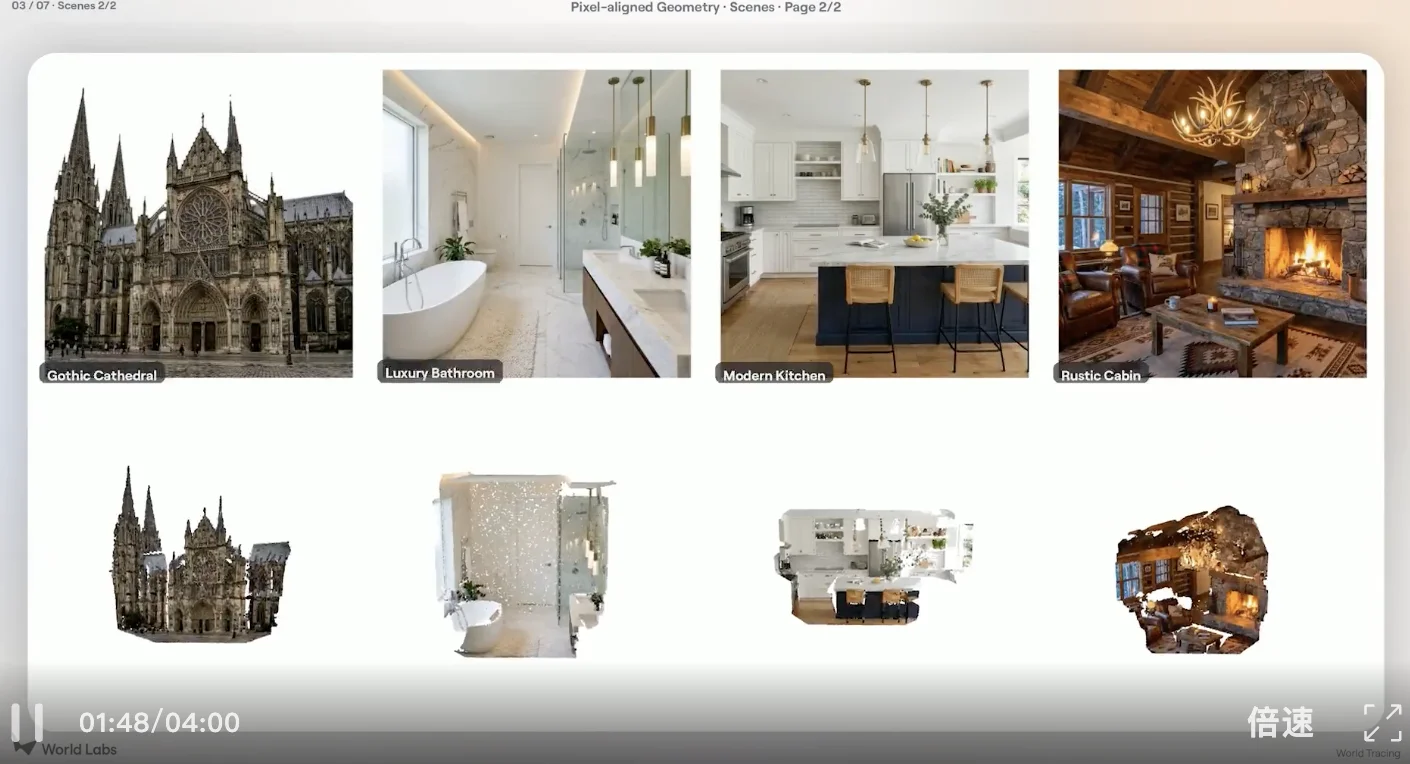
🌐 World Tracing: Pixel-Aligned Multilayer Geometry Beyond the Visible
“Let every pixel point to a full 3D world.”
Traditional single-image 3D reconstruction faces a trade-off:
– Depth estimation → accurate but surface-only;
– Generative completion → rich but often hallucinatory.
World Tracing bridges both — by predicting not just one 3D point per pixel, but an ordered stack of 3D coordinates along each viewing ray:
– Layer 0 = visible surface;
– Deeper layers = occluded geometry behind foreground objects.
This pixel-aligned multilayer XYZ stack preserves strict fidelity to input imagery while enabling deep geometric reasoning.

Key Details:
- Title: World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
- arXiv: 2606.13652
- Project Page: haoz19.github.io/world-tracing-page
- Lead: Hao Zhang; collaborators include Ben Mildenhall, Christoph Lassner, Gengshan Yang
The method uses diffusion modeling over ordered depth values, enabling probabilistic, uncertainty-aware inference — critical when reconstructing unobserved geometry. It supports static scenes, indoor/outdoor environments, and even dynamic world modeling — with open code, Hugging Face demo, and interactive project site.
🧠 Modality Forcing: Unifying Generation & Perception in One Diffusion Model
“One model, fluent in color, text, and depth.”
Image generation and depth estimation have historically lived in silos — requiring separate architectures, data, and objectives. But what if one pre-trained text-to-image model could also perceive spatial structure?
Modality Forcing answers yes — by introducing per-modality noise scheduling in diffusion training:
– RGB and depth channels receive independent noise levels;
– Losses are computed separately per modality;
– At inference, fixing one modality’s noise to zero enables conditional generation (I→D or D→I), or joint synthesis.
Crucially, depth is modeled directly in pixel space, enabling learning from sparse real-world depth annotations — no need for synthetic, densely labeled datasets.
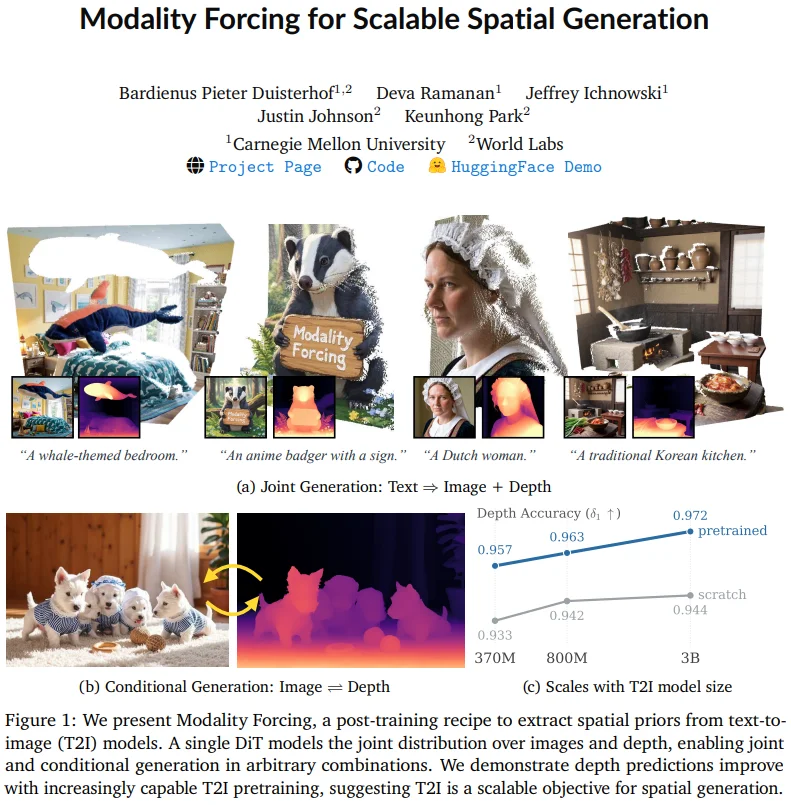
Key Details:
- Title: Modality Forcing for Scalable Spatial Generation
- arXiv: 2606.13676
- Project Page: modality-forcing.github.io
- Lead: Bardienus Duisterhof (World Labs intern)
Unlike prior multi-task models (e.g., Marigold, Depth Pro), Modality Forcing treats generation and perception as two sides of the same diffusion process. This unified capability directly strengthens World Labs’ Marble platform — ensuring consistent, self-aligned 3D world generation without cascaded errors between depth estimation and rendering modules.

🧍 Flex4DHuman: From Monocular Video to Synthesizable 4D Human Avatars
“Lift a smartphone video into dynamic, editable 4D space.”
Reconstructing moving humans from a single camera remains deeply underconstrained. Most methods rely on explicit priors: SMPL skeletons, depth maps, or normal renderings — limiting generalizability and requiring heavy post-processing.
Flex4DHuman eliminates those dependencies. Built atop Alibaba’s Wan 2.1 video DiT (1.3B params), it replaces standard spacetime position encoding with a novel five-axis positional encoding, incorporating:
– Spatial x/y/z coordinates
– Frame index
– Viewpoint slot index
– Continuous SE(3) relative camera pose
This lets attention mechanisms internally reason about camera geometry, enabling synchronized multi-view video synthesis — all from a single monocular reference clip.

Key Details:
- Title: Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
- arXiv: 2606.13655
- Project Page: andy-cheng.github.io/Flex4DHuman
- Lead: Yipeng Wang; First Author: Jen-Hao Cheng
Output multi-view videos are fed into FreeTimeGS, producing editable 4D Gaussian Splats — enabling animation, scene insertion, and AR/VR integration. Remarkably, the model generalizes beyond humans to animals — validating its geometry-agnostic design.
Benchmark results show +9.3 dB PSNR vs. Diffuman4D-mono-skeleton on DNA-Rendering and +3.4 dB on zero-shot ActorsHQ — proving robustness and scalability.

🚪 Leadership Transition: Christoph Lassner Steps Down as Co-Founder
On the same day as the paper release, co-founder Christoph Lassner announced his departure from World Labs’ day-to-day operations.
A pioneer in 3D vision (ex-Bodylabs/Amazon Halo, Meta Reality Labs, Epic Games), Lassner contributed foundational expertise in neural rendering and NeRF. His name appears in all three paper acknowledgments — confirming active involvement during development.
In his public statement, he cited recovery from serious personal injuries (including fractures and concussion) as prompting reflection — leading to a decision to step back from executive duties. He will continue advising the company.

✅ Conclusion: A Strategic Academic Debut
These three papers represent more than incremental research — they signal World Labs’ commitment to open, rigorous, and community-engaged spatial intelligence development. While Marble, World API, and Spark 2.0 previously defined the company’s product identity, this arXiv debut establishes its academic foundation.
As Justin Johnson stated: “3D is exciting — we’re still figuring out the right tasks, formulations, architectures, and scaling laws. Here are some ideas — led by exceptional interns.”
With $10B+ valuation and backing from NVIDIA, AMD, Adobe, Databricks, and Autodesk, World Labs is now formally inviting the global research community to collaborate — one pixel, one ray, one frame at a time.