World Labs Publishes Three Groundbreaking 3D Generation Papers
Today, World Labs — the spatial intelligence company co-founded by AI pioneer Fei-Fei Li — unveiled three peer-reviewed technical papers on arXiv in a single day. All three were led by internal interns and converge on a shared vision: leveraging mature 2D generative models to dramatically lower the barrier to high-fidelity 3D content creation.
“These are our first-ever papers,” affirmed Justin Johnson, co-founder of World Labs — marking a pivotal transition from product demos and API releases to formal academic contribution.
Why This Matters: The 3D Generation Challenge
3D content generation remains notoriously difficult: real-world data is inherently 3D, yet >99% of available training data (photos, videos, web images) is 2D — lacking depth, occlusion relationships, and volumetric structure. Traditional approaches require expensive multi-view captures, dense 3D annotations, or complex optimization pipelines.
World Labs’ trio of papers advances a powerful alternative: distill spatial intelligence from existing 2D foundation models, enabling robust, scalable, and accessible 3D reasoning — no specialized hardware or datasets required.

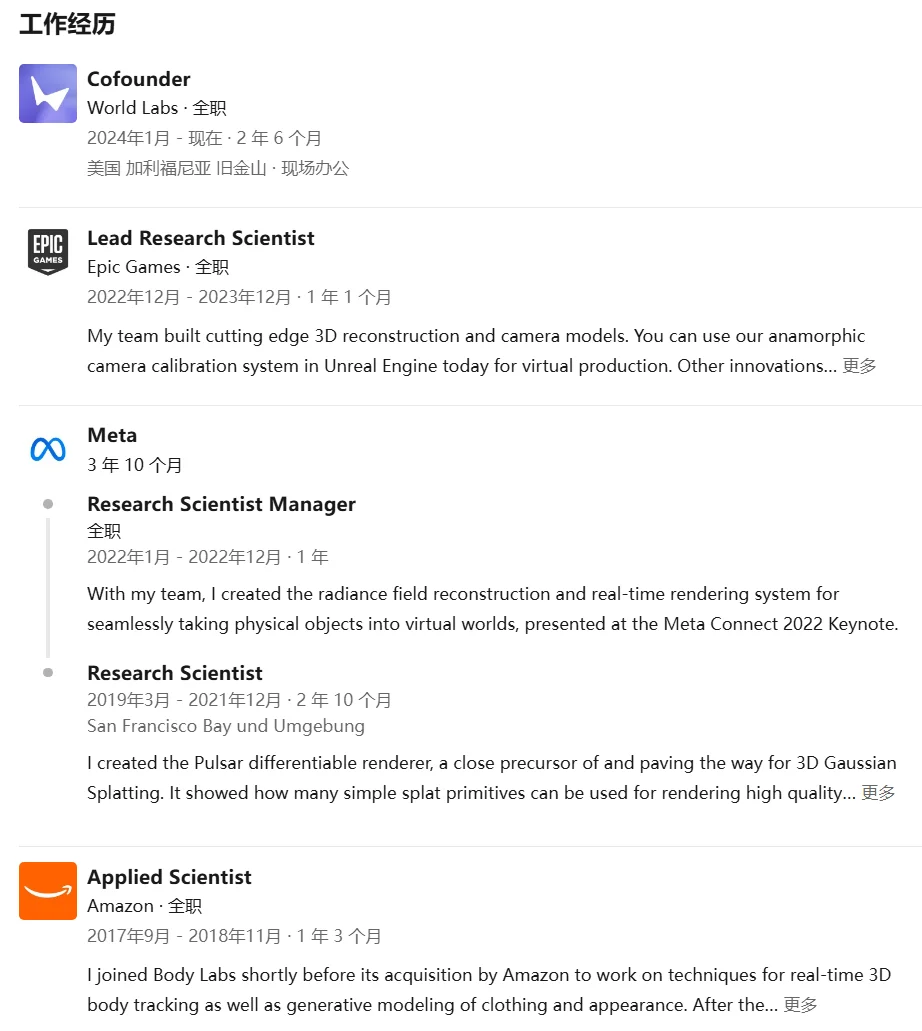
Paper 1: World Tracing — Pixel-Aligned Multilayer Geometry
“Let every pixel point to a complete 3D world.”
Core Innovation
Instead of predicting a single depth value per pixel, World Tracing introduces a pixel-aligned multilayer XYZ stack — modeling not just visible surfaces, but ordered layers of occluded geometry along each camera ray (e.g., foreground object → wall → furniture behind).
This enables faithful reconstruction beyond the visible, grounded precisely in input image pixels.

Key Details
- Title: World Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
- Lead Author: Hao Zhang (World Labs intern)
- Team: Ben Mildenhall, Christoph Lassner, Gengshan Yang
- Code & Demo: haoz19.github.io/world-tracing-page
- Technical Insight: Uses diffusion modeling over multilayer depth tensors — ideal for uncertain, probabilistic geometric inference.
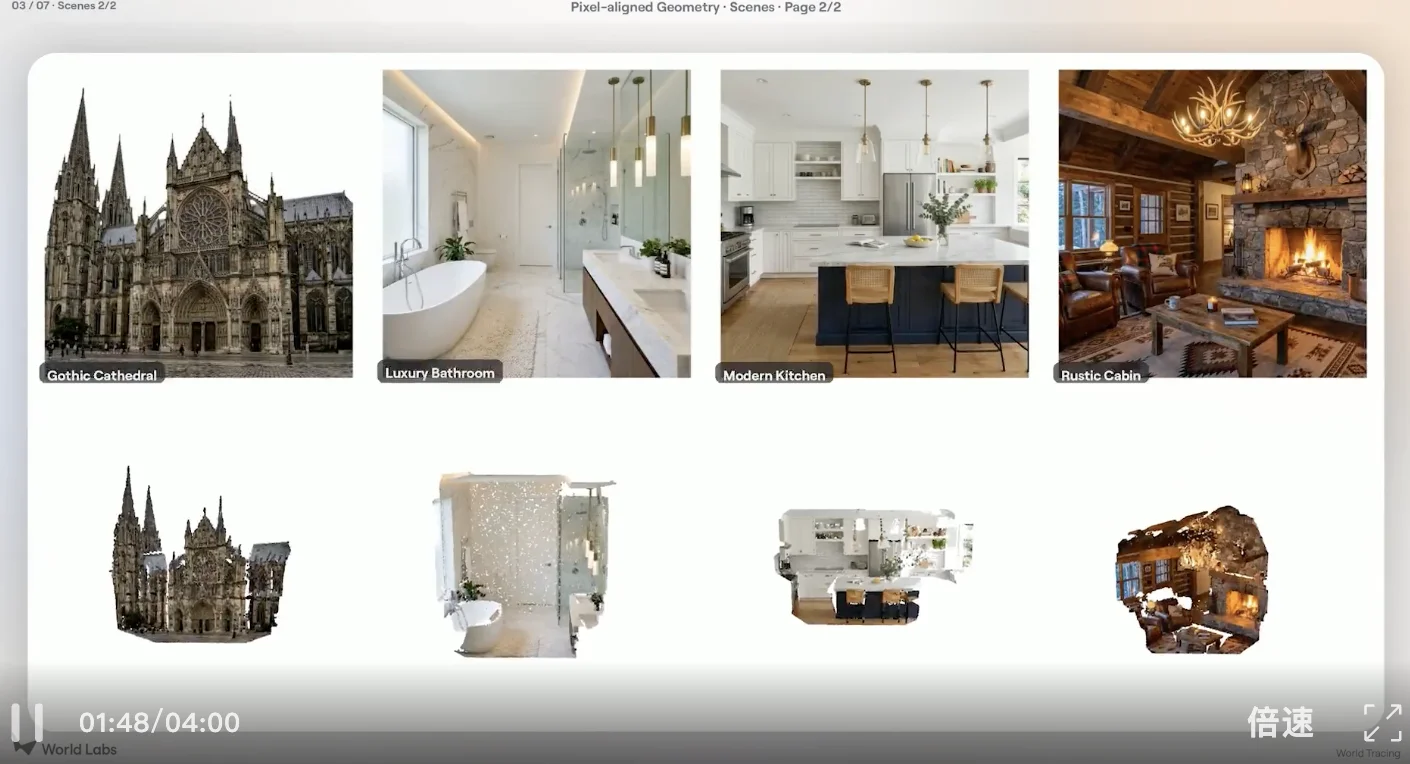
For World Labs’ flagship product Marble, this unlocks single-image-to-explorable-3D-world generation — eliminating need for multi-view inputs or manual labeling.
Paper 2: Modality Forcing — Unified RGB + Depth Generation
“One model, fluent in color, text, and depth.”
Core Innovation
Modality Forcing bridges the gap between discriminative (depth estimation) and generative (text-to-image) tasks. It trains a single diffusion model to jointly generate RGB images and depth maps — using independent noise schedules per modality.
At inference: fix RGB → generate depth (I2D), fix depth → generate RGB (D2I), or jointly denoise both.
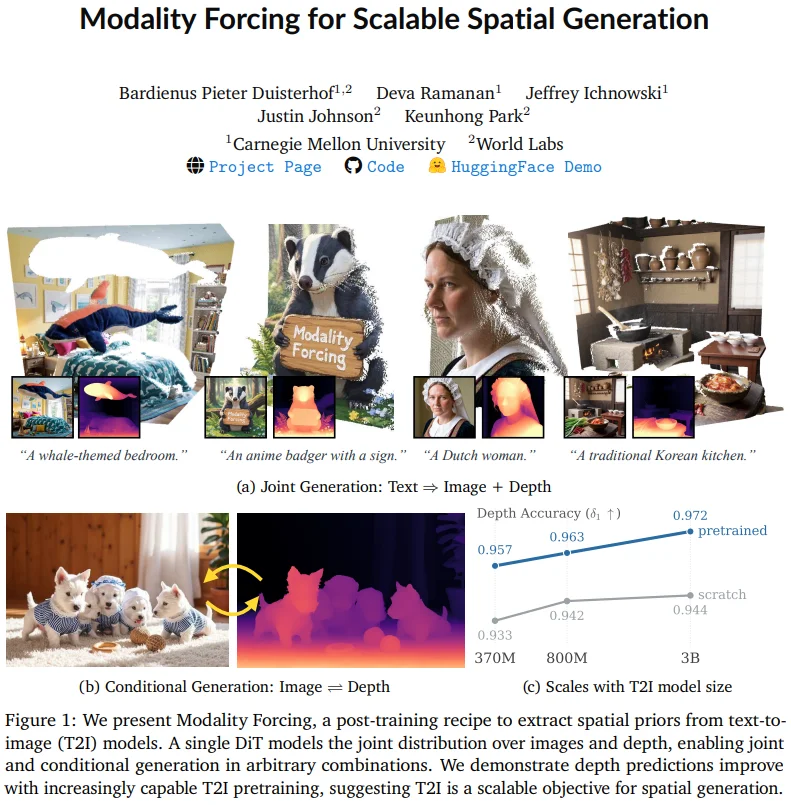
Key Details
- Title: Modality Forcing for Scalable Spatial Generation
- Lead Author: Bardienus Duisterhof (World Labs intern)
- Code & Site: modality-forcing.github.io
- Breakthrough: Learns depth perception directly from sparse real-world depth data — no synthetic LiDAR required.

This unification eliminates error propagation between separate depth and generation modules — critical for coherent, physics-aware 3D world building in Marble.
Paper 3: Flex4DHuman — From Smartphone Video to Dynamic 4D Humans
“Lift a phone video into a synthesizable, animated 4D human asset.”
Core Innovation
Flex4DHuman reconstructs dynamic 4D humans (3D + time) from monocular video only. It replaces standard spatiotemporal position encoding with a five-axis positional encoding, embedding relative camera poses directly into attention — enabling synchronized multi-view video generation without skeletons, depth maps, or normals.

Key Details
- Title: Flex4DHuman: Flexible Multi-view Video Diffusion for 4D Human Reconstruction
- Lead Authors: Jen-Hao Cheng (intern), Yipeng Wang (project lead)
- Code & Demo: andy-cheng.github.io/Flex4DHuman
- Performance: +9.3 dB PSNR over Diffuman4D on DNA-Rendering; +3.4 dB on zero-shot ActorsHQ.

The result? A dancer or walker in your phone video becomes a fully controllable 4D Gaussian Splat — ready for AR insertion, virtual production, or digital twin workflows.
Leadership Transition: Christoph Lassner Steps Down
In parallel with the paper release, co-founder Christoph Lassner announced his departure from day-to-day operations due to recovery from a serious accident (including fractures and concussion). He will continue as an advisor.
A foundational figure in 3D computer vision — formerly at Body Labs (acquired by Amazon), Meta Reality Labs, and Epic Games — Lassner contributed significantly to all three papers. His departure marks the end of an era, but also underscores World Labs’ strong institutional knowledge transfer and research continuity.

Conclusion: A New Chapter for Spatial Intelligence
These three papers represent World Labs’ formal academic debut — shifting from stealth R&D and closed beta products to open, reproducible science. As Justin Johnson stated:
“3D is exciting — we’re still figuring out the right tasks, architectures, and scaling laws. We’re sharing ideas driven by exceptional interns.”
With $1.23B total funding (NVIDIA, AMD, Adobe, Autodesk), a rapidly expanding API ecosystem (World API, Spark 2.0), and now rigorous peer-reviewed foundations, World Labs has cemented its role at the forefront of spatial foundation models — turning everyday 2D data into immersive, editable, and intelligent 3D worlds.