Video-MME-v2 Unveils AI’s Video Understanding Gap

A groundbreaking new benchmark — Video-MME-v2 — has been released by the Nanjing University team led by Prof. Chaoyou Fu, in collaboration with Google Gemini’s evaluation team. Designed to expose the widening chasm between inflated benchmark scores and real-world video understanding capability, Video-MME-v2 introduces a paradigm shift in multimodal evaluation.
🌟 Key Highlights
- Human vs. Model Gap: Human experts achieve a 90.7 non-linear group score, while the strongest commercial model (Gemini-3-Pro) scores only 49.4 — less than half of human performance.
- 3300+ Human Hours: Built with rigorous annotation: 12 annotators + 50 independent reviewers, 5 rounds of cross-validation, and 800 high-quality videos (3,200 questions).
- Three-Tier Capability Framework:
- Level 1: Information retrieval & aggregation across frames and modalities
- Level 2: Temporal reasoning — causality, state transitions, event sequencing
- Level 3: Complex, open-ended inference — explanation, synthesis, contextual grounding
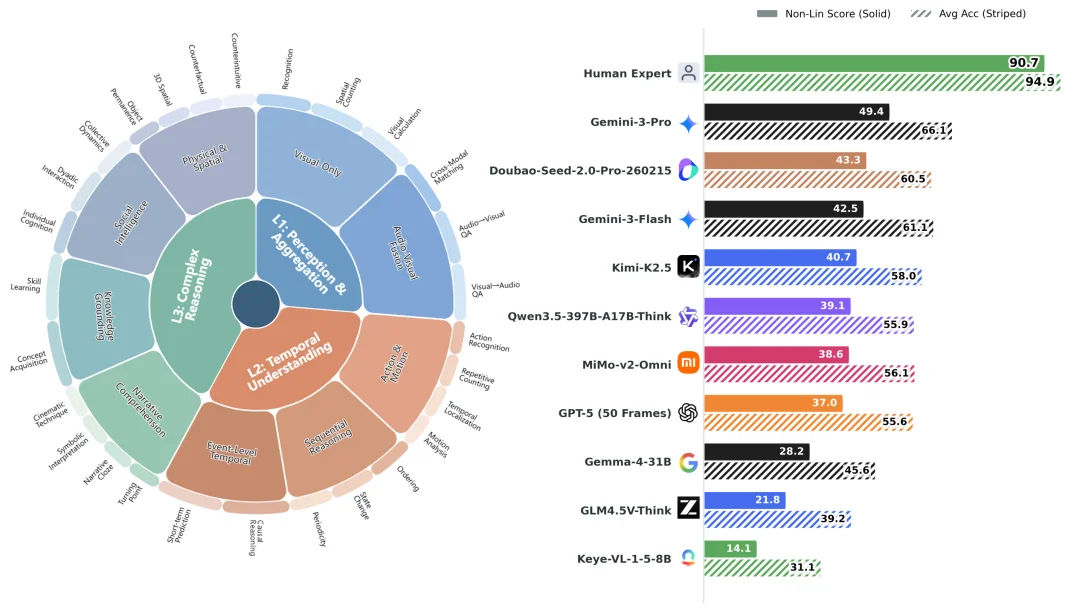
Figure 1: Video-MME-v2’s hierarchical capability structure and top-performing models
🔧 Revolutionary Evaluation Methodology
✅ Group-Level Non-Linear Scoring
Unlike traditional per-question accuracy (Avg Acc), Video-MME-v2 evaluates consistency and coherence across semantically related question groups:
| Group Type | Core Objective | Scoring Mechanism |
|---|---|---|
| Capability Consistency Group | Does the model truly master a skill across varied formulations? | Incentive scoring: Higher rewards for answering all related questions correctly — penalizing fragmented success |
| Reasoning Coherence Group | Can it follow multi-step logic without breaking? | First-error truncation: Any misstep nullifies downstream credit — no “lucky correct answers” |
⚖️ Why It Matters
- Avg Acc for Gemini-3-Pro: 65.9 → Non-Lin Score: 49.4 → Non-Lin/Acc Ratio = ~75%
- LLaVA-Video-7B: Ratio drops to ~40%, revealing severe instability.
- This ratio quantifies robustness decay: lower values signal brittle, non-generalizable reasoning.
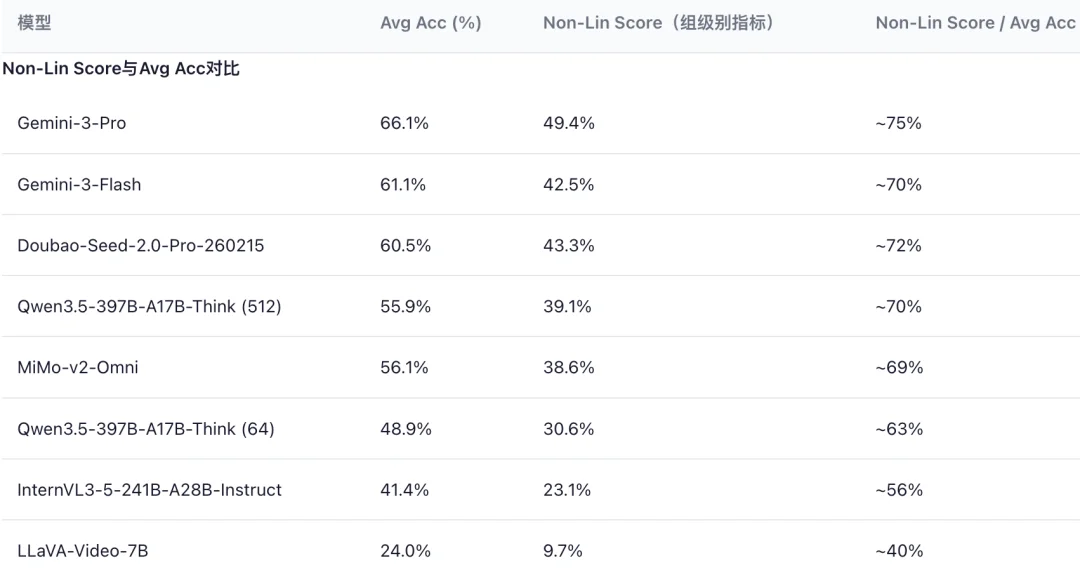
Figure 3: Non-Lin Score / Avg Acc ratio — a robustness diagnostic metric
💡 Critical Insight: “Thinking” Isn’t Always Better
Contrary to prevailing assumptions, enabling chain-of-thought (CoT) reasoning does not universally improve performance:
- ✅ Boost with text cues: Qwen3.5-122B gains +3.8/+5.8 points with subtitles, confirming language anchors strengthen reasoning.
- ❌ Degradation without text: KimiVL-16B drops −3.3 overall and −4.0 on Level 3 tasks; Qwen3-VL-8B falls −0.6 under pure visual conditions.
Takeaway: Current “thinking” is often language-dependent — not grounded in reliable multimodal evidence. When textual scaffolding is absent, CoT may amplify hallucination over insight.
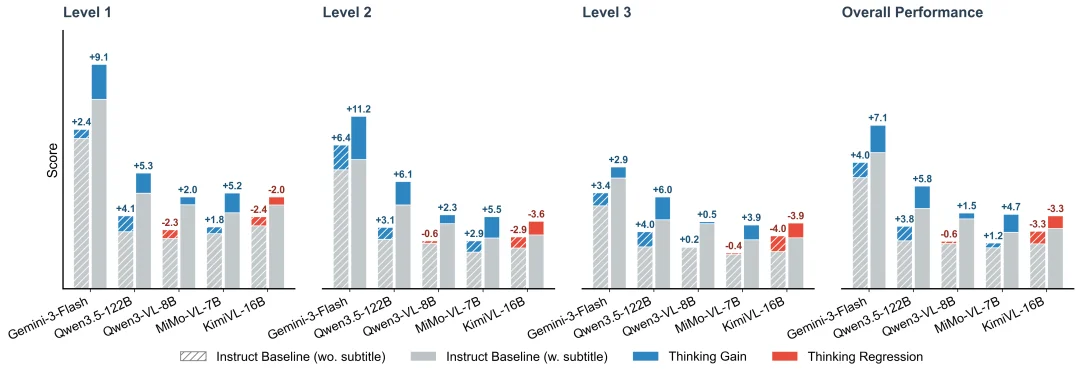
Figure 4: Performance delta from enabling Thinking — highly contingent on subtitle availability
📚 Resources

Prof. Chaoyou Fu, Nanjing University — Lead of Video-MME series, IEEE Biometrics Council Best Dissertation Award winner, Google Scholar citations >8,700
🧩 Why This Benchmark Changes Everything
Video-MME-v2 moves beyond “more questions” to ask: Can the model understand like a human — continuously, dynamically, and coherently? Its layered design, group-aware scoring, and empirical findings expose critical flaws in current evaluation — from metric inflation to ungrounded reasoning — setting a new standard for trustworthy multimodal AI assessment.
“The goal isn’t to rank models — it’s to reveal where they fail, why they fail, and how we must rebuild.”
Source: Machine Heart (adapted and translated for global AI research community)