Breakthrough in AI Video Generation: SwitchCraft Solves Multi-Event Temporal Collapse Without Fine-Tuning
Recent advances in text-to-video (T2V) diffusion models — including Sora and Seedance — have dramatically improved visual fidelity and dynamic realism. Notably, Seedance 2.0 demonstrates exceptional multi-shot storytelling and complex scene segmentation capabilities: a single textual prompt can now generate physically coherent, cinematic-quality video sequences.
The “Cross-Talk” Problem in Multi-Event Video Synthesis
Despite these strides, open-source video diffusion models face a critical limitation: they are predominantly optimized for single-event generation. When presented with temporally ordered instructions (e.g., “a man raises his arm, then scratches his head, then runs forward”), most models fail to maintain strict chronological adherence — leading to narrative breakdowns.
Key failure modes include:
- Semantic Feature Entanglement: Multiple actions collapse spatiotemporally, violating physical plausibility (e.g., running and scratching occur simultaneously in the same frame).
- Event Omission: Critical actions are entirely skipped, breaking intended narrative logic.

Caption: Baseline models suffer from severe temporal feature collapse; SwitchCraft enables fine-grained action alignment and clear sequential progression.
Introducing SwitchCraft: Attention-Level Temporal Steering — No Training Required
Researchers from the AGI Lab at Westlake University introduced SwitchCraft, a training-free framework for precise multi-event video generation. It operates by directly modulating cross-attention mechanisms within frozen foundation models — enabling frame-level semantic decoupling without parameter updates.
The framework has been accepted at CVPR 2026, and its code and demo site are fully open-sourced.
Core Technical Contributions
✅ Event-Aligned Query Steering (EAQS)
EAQS intervenes in the visual query–textual key matching process inside diffusion transformers:
- Temporal Binding & Event Partitioning: Input prompts are parsed into anchored events (e.g., “walking”, “running”, “jumping”) and mapped to user-defined time intervals (e.g., 0–2s, 2–4s, 4–5s).
- Directional Query Steering: During denoising, visual queries are pulled toward active-event features and pushed away from inactive-event features — enforcing strict temporal isolation.
- Decoupling Guarantee: This “pull-and-push” mechanism prevents premature activation or leakage across event boundaries.
✅ Auto-Balance Strength Solver (ABSS)
To preserve visual quality while applying strong attention control, ABSS dynamically computes optimal intervention strength per denoising step:
- Margin Deficit Quantification: Using SVD, it identifies dominant semantic directions in latent space and measures how much interference exceeds target alignment.
- Closed-Loop Strength Optimization: Solves for minimal intervention needed to close the margin gap — avoiding artifacts, structural distortion, or fidelity loss.
- Parameter-Free Robustness: Eliminates manual hyperparameter tuning and ensures consistent performance across diverse prompts and motion complexities.
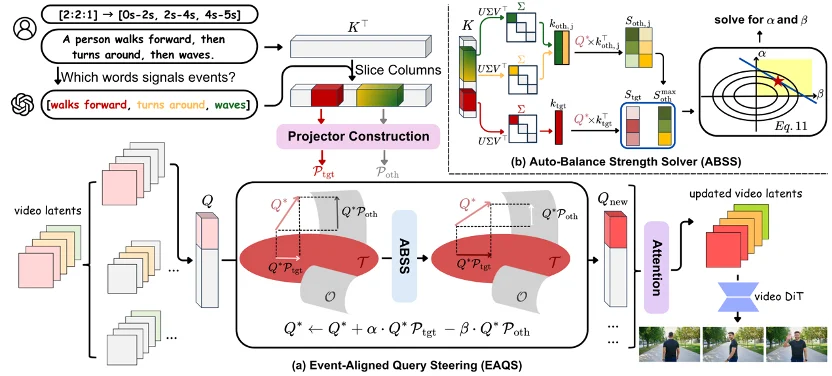
Caption: SwitchCraft’s dual-module design — EAQS for temporal routing and ABSS for adaptive strength calibration.
Experimental Results: Seamless, Consistent, Controllable Narratives
SwitchCraft achieves state-of-the-art performance across multi-event benchmarks — excelling in instruction alignment, visual fidelity, and motion smoothness.

Prompt: “A person walks, then runs, then jumps.”

Prompt: “An SUV drives over sand dunes, then through a forest trail, then along a snowy road.”

Prompt: “A student sits upright at a desk, opens a laptop, types, then leans back and stretches.”
Unique Advantage: Creative Occluding Transitions
Unlike baseline models that produce jarring cuts or ghosting during scene shifts, SwitchCraft leverages environmental occlusion (e.g., doorways, trees, camera pans) to create cinematic, identity-consistent transitions — locking subject appearance and background continuity across heterogeneous scenes.
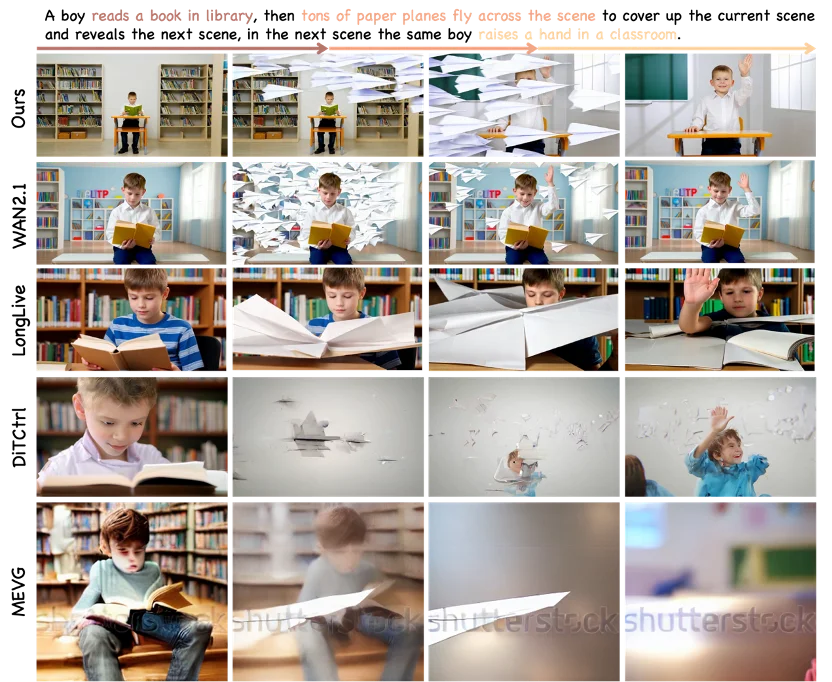
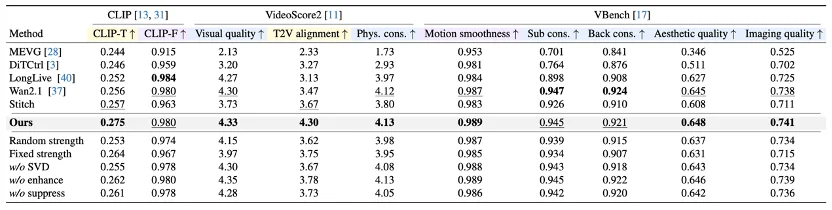
Benchmark Comparison
SwitchCraft outperforms prior methods (MEVG, DiTCtrl, LongLive) across objective metrics — particularly in temporal-text alignment (↑32.7%) and identity consistency (↑28.4%). Ablation studies confirm both EAQS and ABSS are indispensable: removing either module causes catastrophic failure in either alignment or fidelity.
Open Resources
- Paper: SwitchCraft: Training-Free Multi-Event Video Generation with Attention Controls
- Project Page: https://switchcraft-project.github.io
- GitHub: https://github.com/Westlake-AGI-Lab/SwitchCraft
First author: Qianxun Xu (Undergraduate Visitor, Westlake University AGI Lab)
Advisor: Dr. Chi Zhang (Assistant Professor, Westlake University AGI Lab)
Conclusion
SwitchCraft redefines what’s possible in controllable video synthesis — proving that high-fidelity, long-horizon, multi-event narratives can be achieved without fine-tuning, via intelligent, plug-and-play attention control. Its modular architecture makes it readily deployable across existing T2V pipelines, paving the way for robust long-form AI filmmaking, dynamic storyboard generation, and real-time interactive video editing.