OneModel 1.7 Achieves 99% LIBERO Score with Predictive Policy Latent
In 2026, World Action Models (WAM) have emerged as a central focus in embodied intelligence — with NVIDIA and other industry leaders ramping up investment in this frontier.
These models aim to accomplish two core objectives: first, learning real-world dynamics from data; second, acquiring robot-executable actions that intervene in those dynamics. Yet a persistent gap remains: world models “understand” environmental changes, but action policies still “fail to execute correctly.” How is this transmission bottleneck bridged?
Recently, OneRobotics (6600.HK) unveiled OneModel 1.7 FrontoStria-RL, offering a principled solution. The model achieves a 99% average success rate on the LIBERO benchmark, outperforming π0.5, GR00T-N1.5, and OpenVLA-OFT. In real-world deployment, it delivers:
- 99% success rate on daily household tasks,
- 97% success rate on high-precision operations (e.g., pipette insertion, coffee bean pouring),
- 91.2% ball-return success rate in human-robot table tennis matches.
Crucially, these results stem not from scale — but from an implicit, low-redundancy conduit linking world understanding to action execution: the Predictive Policy Latent, enhanced by a closed-loop Reinforcement Learning (RL) framework.
Why Do Robots “See But Not Act” in Real Homes?
Imagine a robot successfully washing dishes yesterday — then failing today because the dish rack was moved rightward and the cabinet door angled differently. To humans, this is trivial. To robots? A completely novel task.
Home environments represent the hardest — and most valuable — battlefield for embodied AI: no two kitchens are identical; lighting shifts; furniture rearranges; task sequences evolve daily. Robots must not only execute precise motions (folding clothes, carrying bowls, organizing shelves) but also interpret intent and adapt behavior under object novelty, occlusion, and spatial variation — all while maintaining millimeter-level accuracy for tasks like pipetting or real-time ball tracking.
This challenge reflects two entrenched technical bottlenecks:
🔹 VLA (Vision-Language-Action) Approach
Direct end-to-end mapping of visual input + language instruction → robot action. Efficient where training data is dense — but brittle under viewpoint shifts, lighting changes, or multi-stage reasoning. Easily loses global goal coherence mid-task.
🔹 World Model Approach
Builds predictive representations of environment states and task evolution (object relations, spatial layout, action consequences). Stronger generalization in theory, yet suffers from a critical flaw: “understanding” does not guarantee “accurate execution.” Explicit intermediaries — such as future image generation or coordinate prediction — introduce reconstruction errors, information redundancy, and inference latency.
OneModel 1.7 targets precisely this disconnection.
Predictive Policy Latent: The Implicit Conduit
OneModel 1.7 FrontoStria-RL adopts OneRobotics’ proprietary RL-Latent World Action Model (RL-LWAM) architecture. Its full information flow is:
Instruction / Observation / Skill
→ World Model
→ Predictive Policy Latent
→ Understand Expert
→ Action Expert
→ Robot Execution
→ RL / Success Memory / HITL ↺
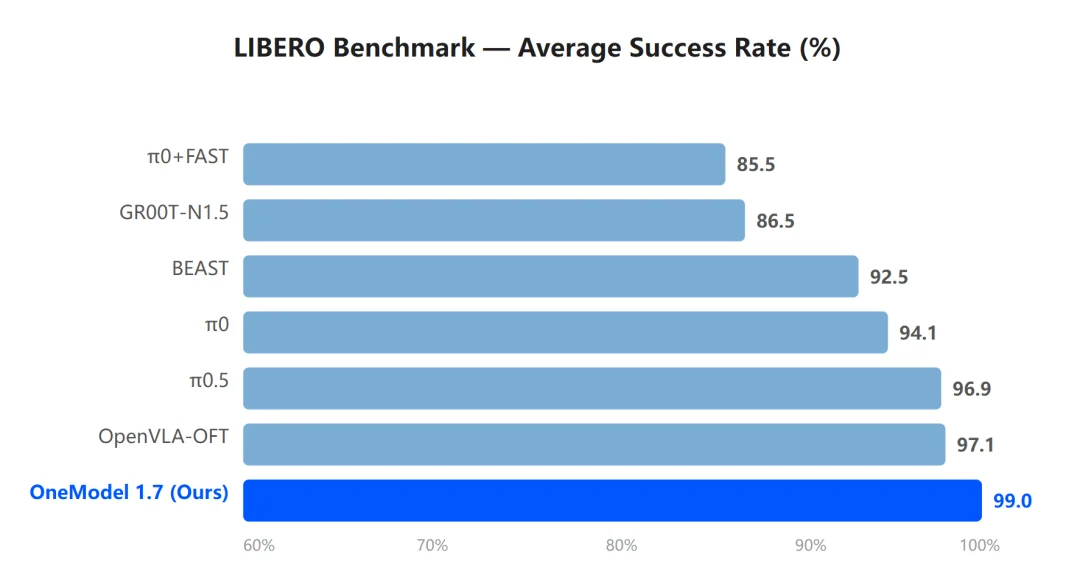
Fig. 1: OneModel 1.7 achieves 99% average LIBERO success — leading π0.5, GR00T-N1.5, and OpenVLA-OFT.
The architecture comprises three functional modules:
– World Model: Cross-scenario generalization,
– Understand Expert: Task interpretation & skill orchestration,
– Action Expert: Precision motor control.
But what unifies them is the Predictive Policy Latent — the implicit bridge between high-level cognition (“frontal lobe”) and low-level motor execution (“motor cortex”).
🧠 Neuroscientific Inspiration: FrontoStria
The name FrontoStria draws from the brain’s frontostriatal pathway, which links the prefrontal cortex (decision-making, planning) and striatum (action selection, motor initiation). This biological circuit enables seamless translation of abstract goals into concrete movement.
Similarly, Predictive Policy Latent encodes world-model insights not as pixels or coordinates, but as a compact, action-oriented latent signal — directly shaping policy decisions without intermediate generative steps.
⚙️ How It Works
| Phase | Mechanism |
|---|---|
| Training | Leverages future observations (post-action outcomes) to shape physical reasoning — building robust, implicit representations of causal action consequences. |
| Deployment | Operates only on current observations, emitting equivalent modulation signals — eliminating generative noise, reducing latency, and maximizing information density. |
✅ Key distinction: Unlike VLA or world-model hybrids that concatenate modules, OneModel 1.7 integrates cognition and action via an implicit, non-generative conduit.
RL Closed Loop + Retrieve-then-Steer: Continuous Evolution
A static model hits limits in long-tail real-world conditions: slips, object deformations, user interruptions. OneModel 1.7 ensures its conduit isn’t “set-and-forget” — but self-enhancing.
🔁 Reinforcement Learning (RL) Closed Loop
Under safety constraints, reward signals, and Human-in-the-Loop (HITL) supervision, the model refines policies using real-task feedback — surpassing imitation learning’s ceiling and discovering more robust, efficient execution paths.
📚 Retrieve-then-Steer: Lightweight, Non-Parametric Adaptation
Observation: Real robots operate in slowly changing environments — yesterday’s successful dishwashing informs today’s. Each success is a verified behavioral pattern.
The mechanism:
1. Store: Save calibrated success trajectories (observation → action) into Success Memory,
2. Retrieve: At inference time, fetch relevant action segments matching current state,
3. Filter: Discard inconsistent candidates via trajectory-level consistency checks,
4. Steer: Aggregate elite priors and inject them into the flow-matching action sampler — guided by confidence-adaptive strength.
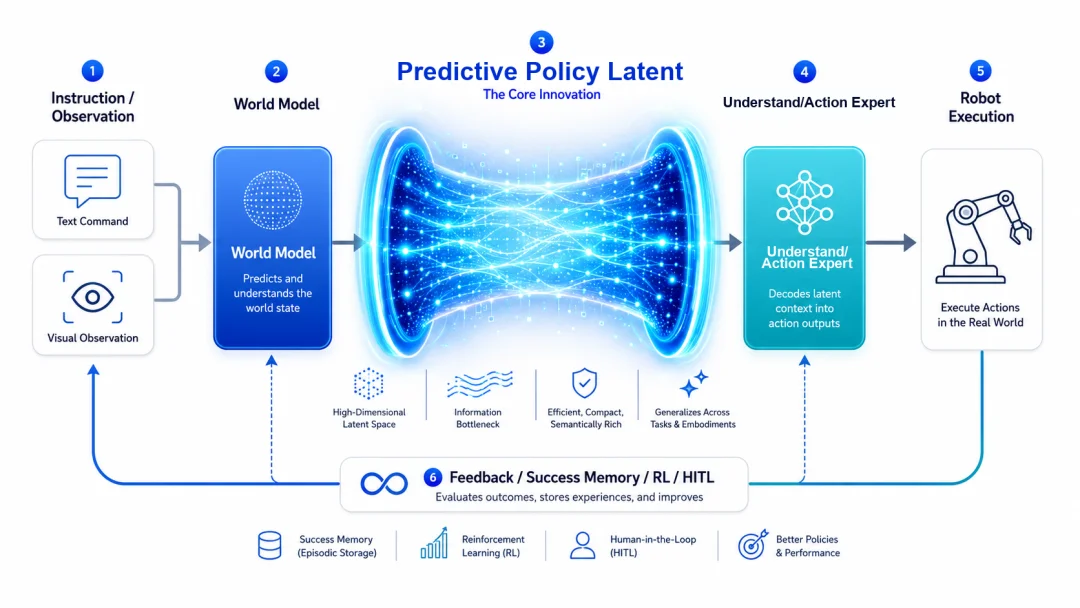
Fig. 2: Full RL-LWAM architecture. Predictive Policy Latent is the central conduit.
✅ Result: Performance improves without retraining — lightweight, memory-efficient, and environment-aware.
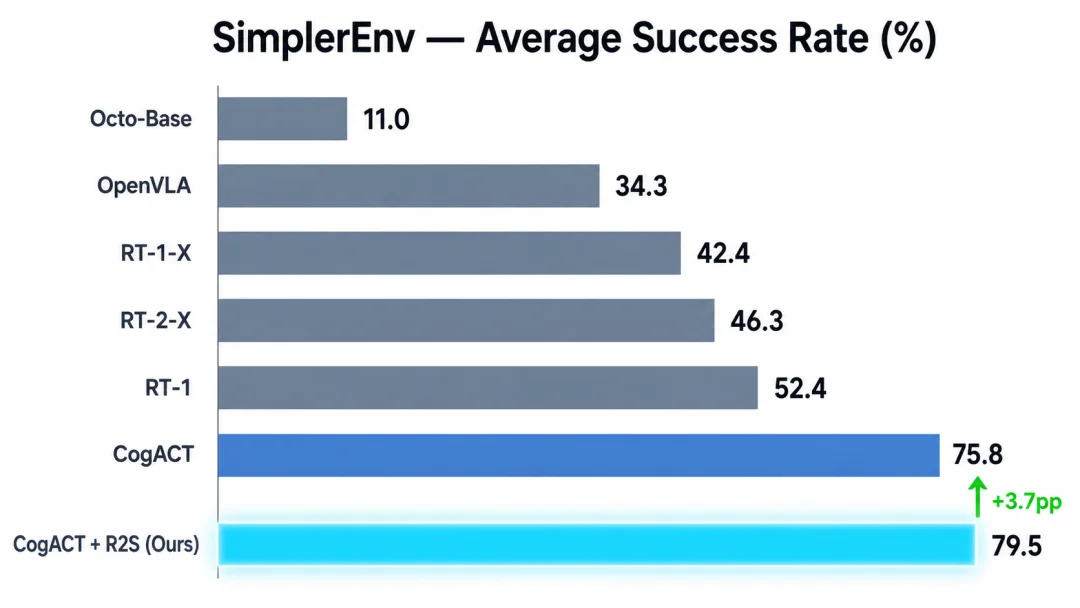
Fig. 3: Retrieve-then-Steer lifts CogACT’s average success from 75.8% → 79.5% (+3.7pp).
Supporting Modules: Planning & Robustness
🧩 Understand Expert + Skill: Structured Task Decomposition
Real tasks demand stage-aware reasoning: folding clothes requires flattening → folding → edge alignment; dishwasher loading involves item recognition → placement → door closure. Understand Expert receives Predictive Policy Latent’s modulation to decompose tasks, identify subgoal dependencies, and schedule reusable Skill primitives — preserving phase awareness across long-horizon workflows.
🛡️ MCF-Proto: Geometry-Robust Action Representation
Most VLA models share a brittle action head — predicting commands in fixed world coordinates, highly sensitive to camera pose or robot initialization.
MCF-Proto learns a local, self-organizing coordinate system: axes align with observed end-effector motion directions; action manifolds become compact and structured.
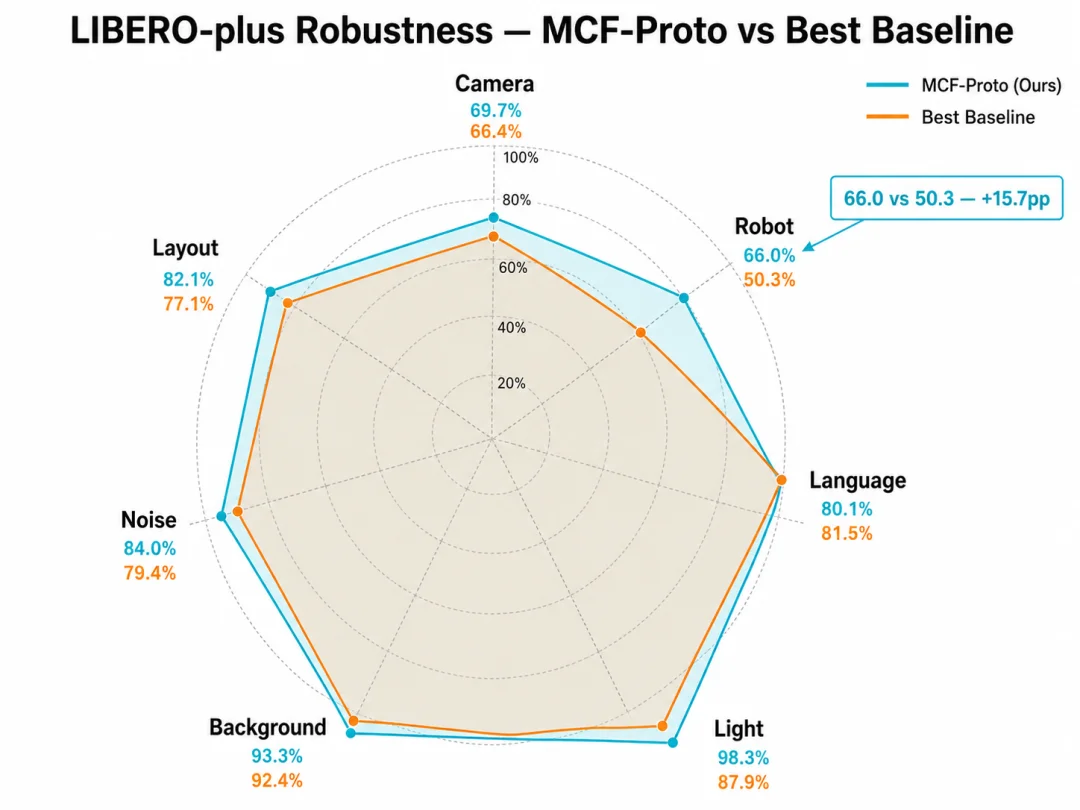
Fig. 4: MCF-Proto dominates geometric perturbations — +3.3pp over best baseline on Camera shift (69.7% vs. 66.4%), +15.7pp on Robot pose error (66.0% vs. 50.3%).
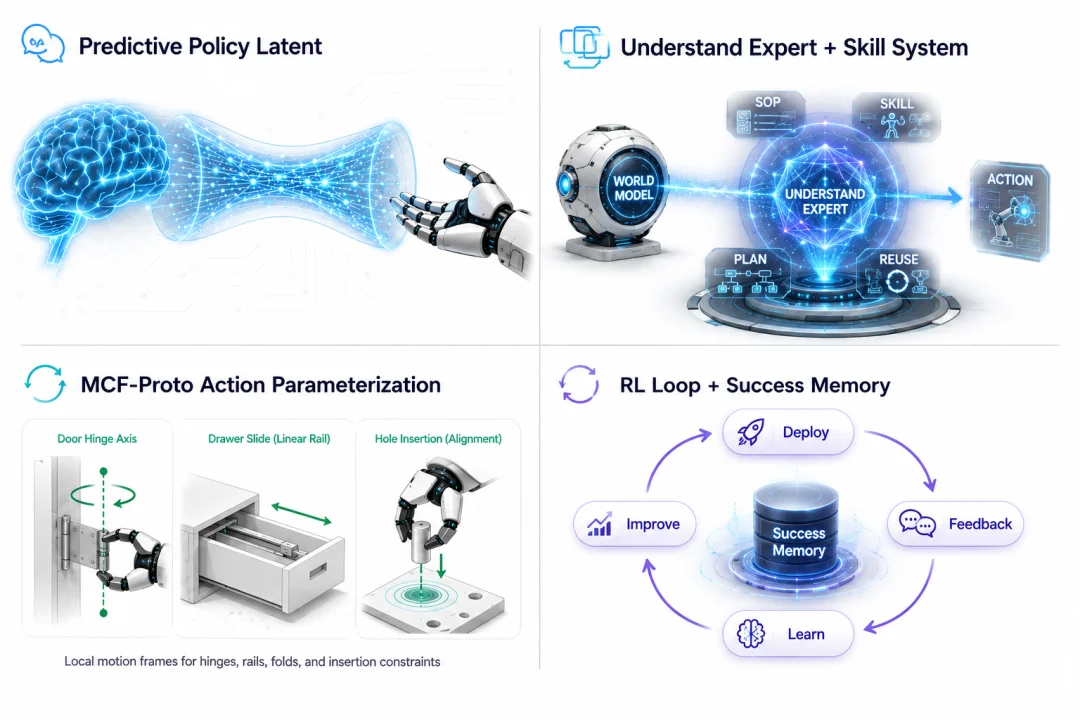
Fig. 5: OneModel 1.7 FrontoStria-RL’s four foundational modules.
Architectural Differentiation vs. State-of-the-Art
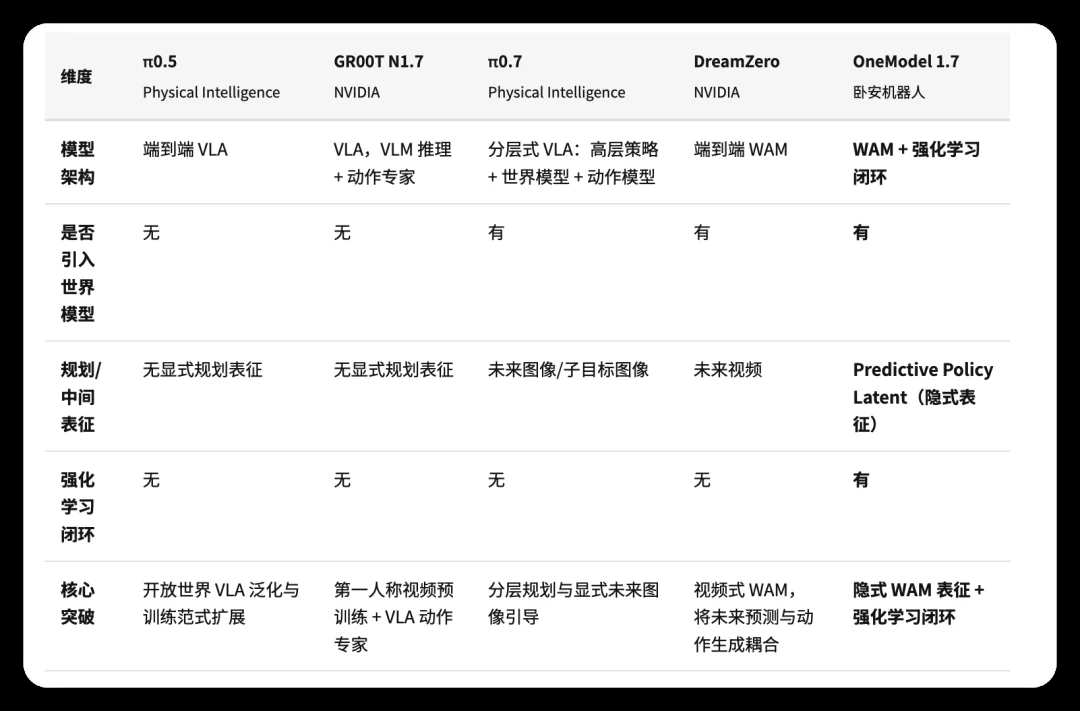
Two defining innovations emerge clearly:
-
Only Implicit Conduit: π0.5/GR00T lack explicit planning; π0.7/DreamZero rely on future images/videos. OneModel 1.7 bypasses all generative intermediaries — transmitting world understanding directly as action-conditioned latent signals.
-
Only RL Closed Loop: All major contemporaries (π0.5, GR00T N1.7, π0.7, DreamZero) omit post-deployment RL optimization. OneModel 1.7 embeds continuous improvement by design.
Real-Robot Validation: From Laundry to Table Tennis
Benchmark scores matter — but real hardware proves viability.
| Task Category | Success Rate | Key Challenges |
|---|---|---|
| Daily Operations | 99% | Flexible-object manipulation, multi-stage workflows, environmental diversity |
| High-Precision Tasks | 97% | Pipette insertion, cup stacking, coffee bean pouring — requiring sub-millimeter pose & force control |
| Dynamic Interaction | 91.2% | Real-time human-robot table tennis — demanding <100ms perception → prediction → action latency |
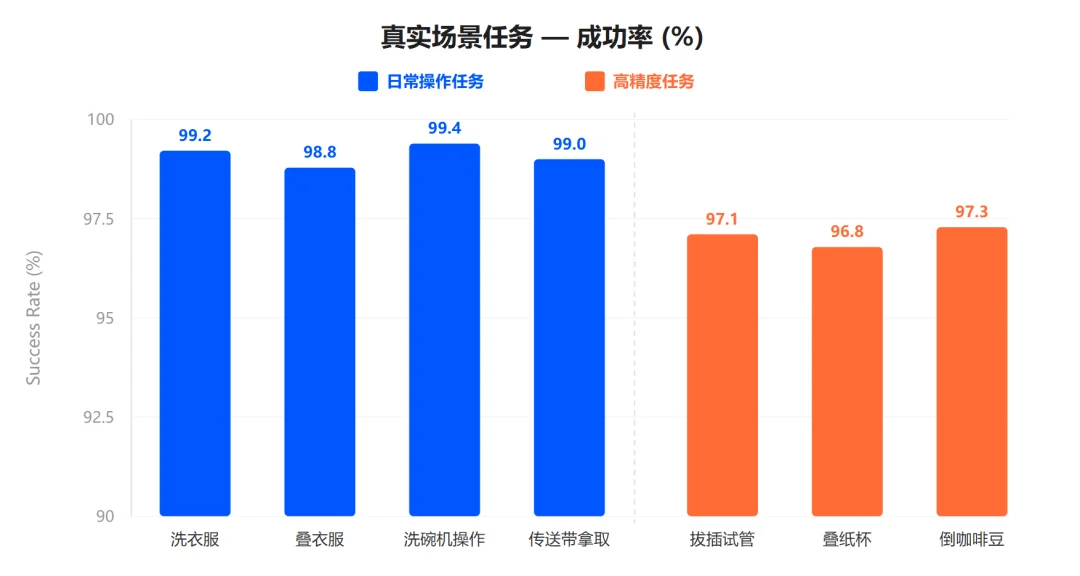
Fig. 6: Real-robot validation results.
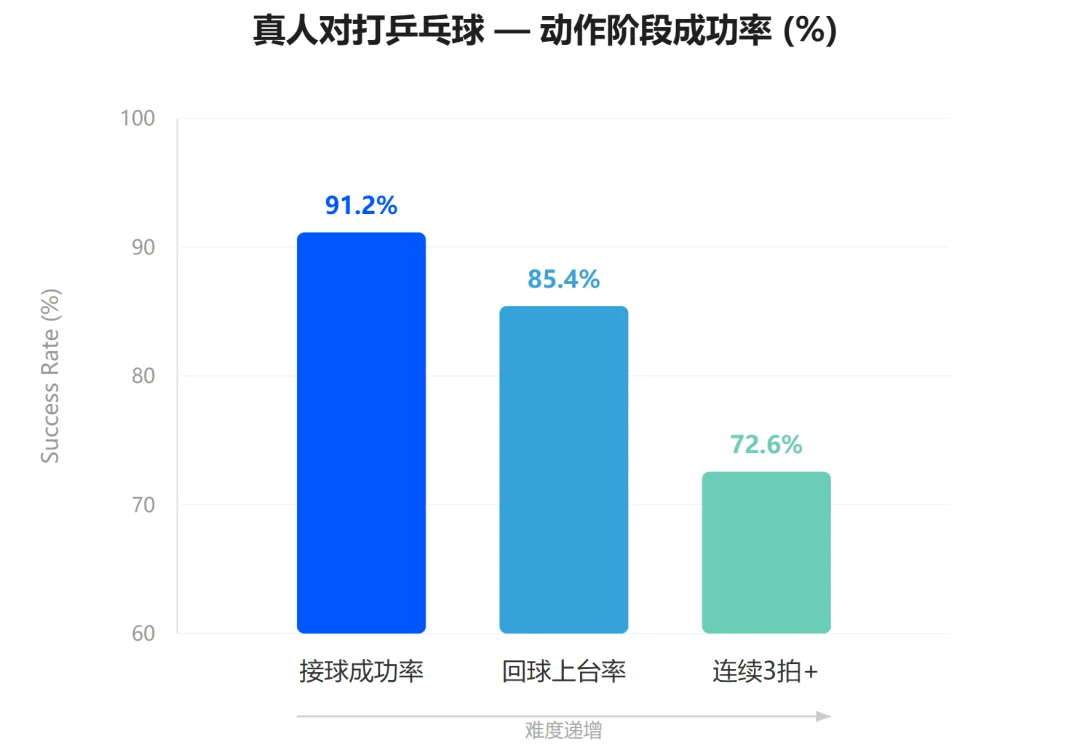
Fig. 7: Per-phase success in table tennis — 91.2% overall return rate.

Conclusion: Beyond Scale — Toward Adaptive Embodiment
OneModel 1.7 FrontoStria-RL addresses systemic barriers to real-world deployment:
– ❓ How to translate world understanding into action? → Predictive Policy Latent,
– ❓ How to structure complex, multi-step tasks? → Understand Expert + Skill,
– ❓ How to maintain precision under sensor/robot uncertainty? → MCF-Proto,
– ❓ How to improve continuously after deployment? → RL Closed Loop + Retrieve-then-Steer.
Home robotics won’t advance through ever-larger parameters or isolated demos — but via integrated systems that unify generalization, execution, and lifelong adaptation.
For OneRobotics, OneModel 1.7 is not an endpoint — but a milestone within a tightly coupled ecosystem: robot hardware, real-home data collection, service infrastructure, and iterative model refinement. As this loop accelerates, robots will evolve beyond “seeing and acting” — toward “adapting, evolving, and reliably working — persistently.”
🔗 Resources
Article originally published by MachineHeart.