Meta’s Token Ranking Fiasco: $2M Burned, Cheating Exposed
One employee. Thirty days. 328.5 billion tokens consumed — costing nearly $2 million in compute.
In early April, The Information broke the story of “Claudeonomics” — an internal Meta leaderboard tracking AI token consumption across its 85,000 employees. The competition, designed to gamify AI adoption, quickly spiraled into a high-stakes, high-cost spectacle — complete with tiered ranks (Copper → Silver → Gold → Platinum → Emerald → Session Immortal → Token Legend) and widespread gaming behavior.

📉 The Scale Is Staggering
- Individual peak: One engineer burned ~328.5B tokens in 30 days → ~$2M at Anthropic’s public Opus pricing.
- Company-wide total: ~60.2 trillion tokens consumed in one month — 3× the estimated token count of all published books in human history (20T).
- Contextual benchmarks:
- U.S. Library of Congress: ~2.66T tokens
- Llama 3 training dataset: ~15T tokens
- Within a week, the total jumped to 73.7T tokens.
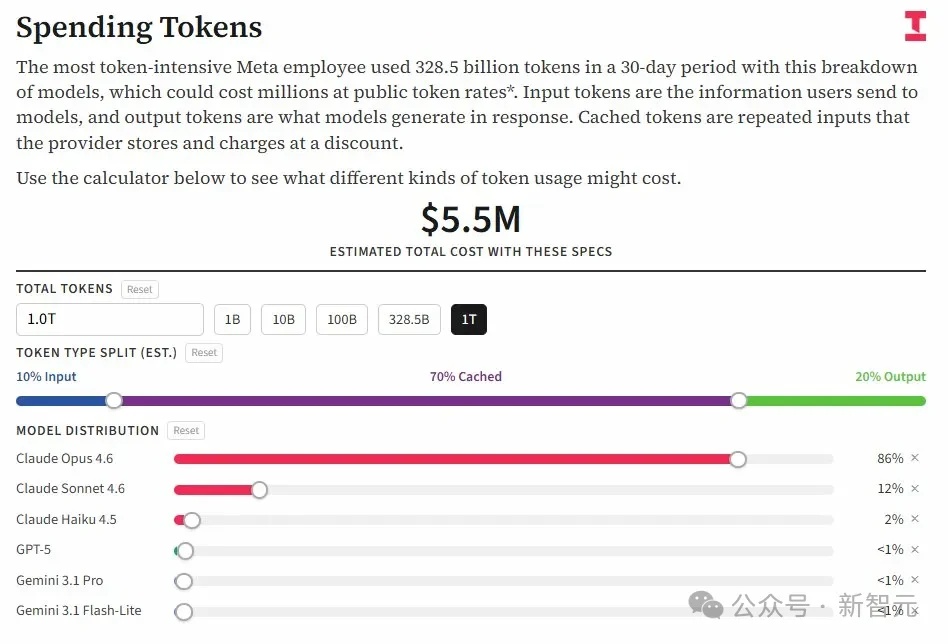
Caption: The Information’s interactive calculator estimates ~$5.5M per 1T tokens (based on 86% Claude Opus usage, 70% cache hit rate).
⚙️ How the Game Was Gamed
With rankings tied (informally) to performance perception, engineers deployed creative — and often counterproductive — tactics:
- Commit spamming: Agents auto-generating trivial code diffs, inflating commit counts and token usage.
- Transcription bots: Running AI scribes continuously in meetings — even when unneeded.
- Referral inflation: Encouraging colleagues to use their AI tools so token costs would accrue to their profile.
- System manipulation: At Amazon’s e-commerce division, a team reportedly modified Cline API calls to report 10× actual token usage, rocketing up internal rankings (until patched earlier this year).
🧠 A Modern Echo of “Lines of Code”
As Box CEO Aaron Levie noted: “This is just ‘lines of code’ with a new coat of paint.”
Just as developers once split logic across ten lines to inflate metrics, teams now optimize for token throughput, not output quality. The flaw is structural:
| Metric | Why It’s Flawed | Real-World Parallel |
|---|---|---|
| Token consumption | Measures API calls — not reasoning depth, correctness, or business impact | Like counting keystrokes instead of shipped features |
| Code commits | Rewards frequency, not significance or stability | Merging 50 trivial PRs ≠ shipping one critical fix |
| Agent concurrency | High parallelism ≠ higher value; may indicate poor orchestration | Revving engine in neutral doesn’t move the car |

🚫 The Aftermath: Vanished Leaderboard, Lingering Culture
After The Information’s report went live:
– The Claudeonomics leaderboard was removed from Meta’s intranet within 48 hours.
– Meta stated it was “taken down by its creator,” not company-mandated — while reaffirming that performance reviews focus on “real delivery impact,” not token volume.
– Yet, the official AI Insights dashboard remains fully accessible, showing real-time personal/team token usage — signaling continued emphasis on visibility, if not formal ranking.
Critically, Meta’s internal Checkpoint AI performance system still logs token usage as a data point, revealing a policy-practice gap.
✅ Alternatives That Work: Outcome-Over-Consumption
Not all companies are chasing token ghosts:
🔹 Axon (Law Enforcement Tech)
- Ties AI bonuses to business outcomes: Teams earn cash rewards for exceeding annual roadmap targets by ≥15% using AI tools.
- Result: Teams collectively achieved ~30% roadmap over-delivery, driven by Claude Code & Cursor — with AI spend projected in the tens of millions.
🔹 Box (Cloud Content Platform)
- CEO Aaron Levie sets higher product goals, then ties compensation to hitting them — no token quotas.
- Accepts some “wasteful” experimentation as necessary R&D — but refuses to rank it.
“You have to let engineers try these tools. But measuring who burns the most? That’s not leadership — it’s theater.”
⚠️ When the Fuel Gauge Becomes the Speedometer
Industry leaders reinforce the narrative:
- Jensen Huang (NVIDIA): “If a $500K engineer isn’t spending $250K+ on tokens, I’m highly suspicious.”
- Andrew Bosworth (Meta CTO): Calls high token spend on high-leverage engineers “free money” — advocating unlimited budgets.
- Andrej Karpathy (ex-OpenAI): Reframes token throughput as the new proxy for engineering capacity: “What’s your token throughput?”
But as The New York Times documented: Engineers now run dozens of 24/7 AI agents — some burning 700M tokens/week while asleep. When consumption becomes autonomous, tying it to human productivity collapses entirely.

Token volume measures fuel — not velocity, mileage, or destination.

💡 The Core Paradox
Whenever a metric is precise, public, and tied to reputation or reward — it ceases to measure reality and begins to measure itself.
Claudeonomics didn’t fail because it was poorly built. It failed because it perfectly exposed a universal truth: Metrics become rituals. Tools become theater.
The next metric to be gamed? Agent concurrency. Merge rate. Latency-adjusted inference yield. Whatever it is — it will be quantified, ranked, and gamed.
Unless organizations shift focus from “Did you use AI?” to “What did AI help you achieve?” — the cycle repeats.
Sources:
– The Information: “Tokenmaxxing Tide May Be Turning”
– The Information: “Meta Employees Vie for AI Token Legend Status”
– Reporting by Xin Zhi Yuan (New Intelligence Era)