Meituan Unveils STAR: Unified Multimodal Model Breaks Understanding-Generation Trade-off
GenEval Score Surpasses 0.91 — SOTA Performance Across Generation, Editing & Comprehension Tasks
🚀 Breakthrough Overview
Meituan’s MM (Multimodal) Research Team has introduced STAR — STacked AutoRegressive Scheme for Unified Multimodal Learning — a novel architecture that resolves the long-standing “zero-sum dilemma” between multimodal understanding and generation. By decoupling capability acquisition through stacked isomorphic autoregressive modules and task-progressive training, STAR achieves simultaneous state-of-the-art performance in comprehension, text-to-image generation, and image editing — without compromising any core ability.
✅ Key Achievements
- GenEval score: 0.91 — highest-ever on semantic alignment benchmark (STAR-7B)
- DPG-Bench: 87.44 — leading complex-scene generation fidelity
- ImgEdit: 4.34 — new SOTA for multi-operation image editing
- Zero degradation in 9 major understanding benchmarks, including VQAv2, OK-VQA, and TextVQA
- Parameter-efficient: STAR-7B adds only 3B parameters to Qwen2.5-VL-7B backbone

⚙️ Core Innovations
1. Stacked-Isomorphic AR Architecture
STAR replaces brittle hybrid designs with a scalable, plug-and-play stack of identical autoregressive (AR) modules — all sharing the same transformer structure as the base model.
| Feature | Benefit |
|---|---|
| Same-layer initialization | New modules inherit top-layer weights — zero feature-mapping overhead |
| Single objective training | Standard next-token prediction — no custom loss or adapter tuning |
| Compact expansion | STAR-3B adds just 1.2B params; STAR-7B adds 3B — ideal for industrial deployment |
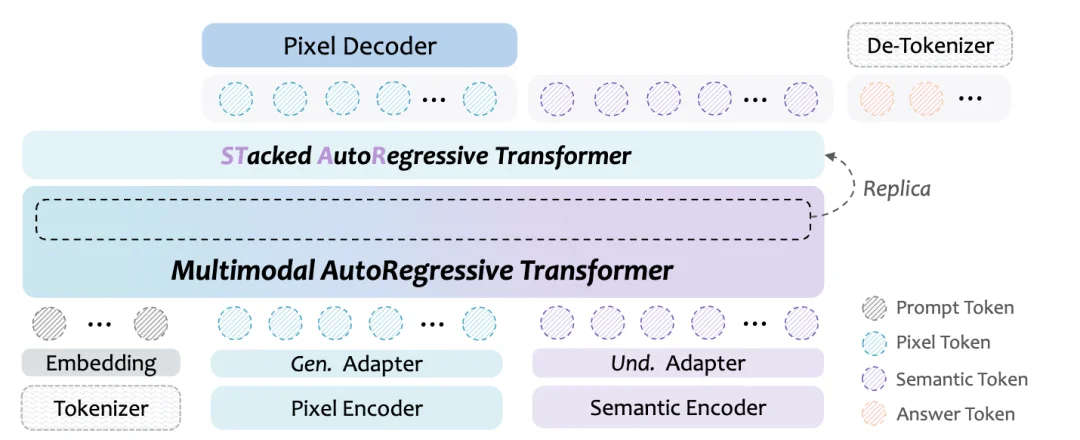
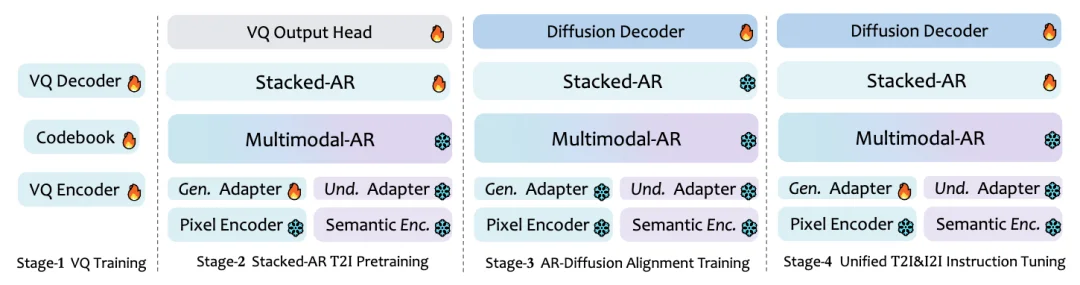
2. Task-Progressive Training Pipeline
Four frozen-stage phases ensure non-interfering capability growth:
- VQ Training: Learn fine-grained visual tokenization via STAR-VQ (65K codebook size, 512-dim vectors)
- Text-to-Image Pretraining: Stack AR modules only — freeze understanding backbone
- AR–Diffusion Alignment: Optimize diffusion decoder separately for pixel fidelity
- Unified Instruction Tuning: Jointly tune stack + decoder using gradient stoppage to protect latent semantics
3. Auxiliary Enhancement Mechanisms
- STAR-VQ Quantizer: Solves codebook collapse with mapping-layer stabilization → richer visual token reconstruction
- Implicit Reasoning: Base model first generates latent reasoning tokens; stacked modules conditionally decode pixels → tighter semantic–pixel alignment
📊 Benchmark Results
🔹 Generation Performance
| Benchmark | Metric | STAR-7B | Prior SOTA |
|---|---|---|---|
| GenEval | Overall Score | 0.91 | 0.87 |
| Object Counting | 1st | 2nd | |
| Spatial Relations | 1st | 3rd | |
| DPG-Bench | Complex Scene Score | 87.44 | 82.11 |
| WISEBench | World Knowledge Score | 0.66 | 0.59 |
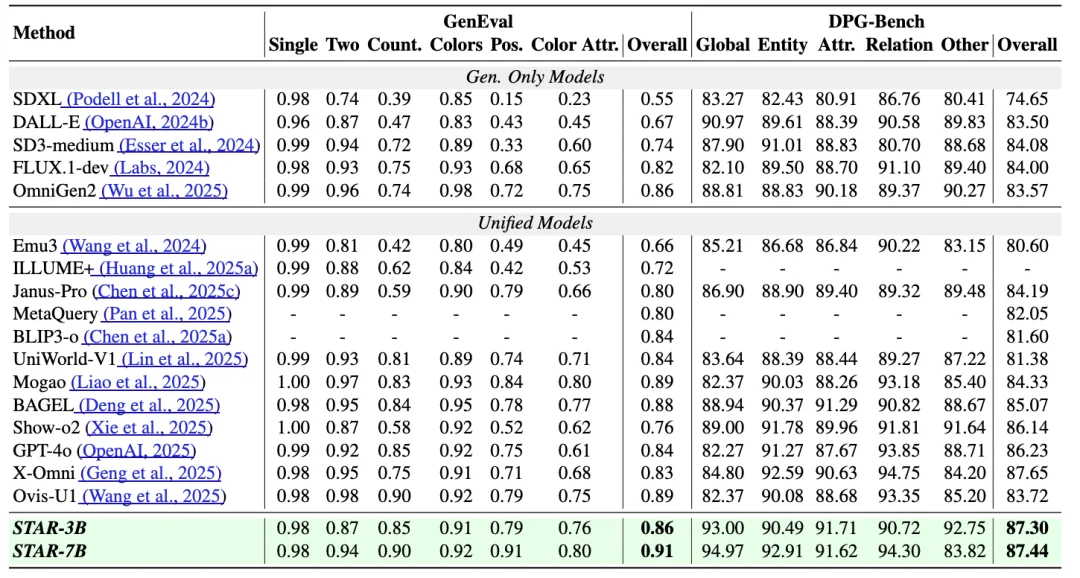
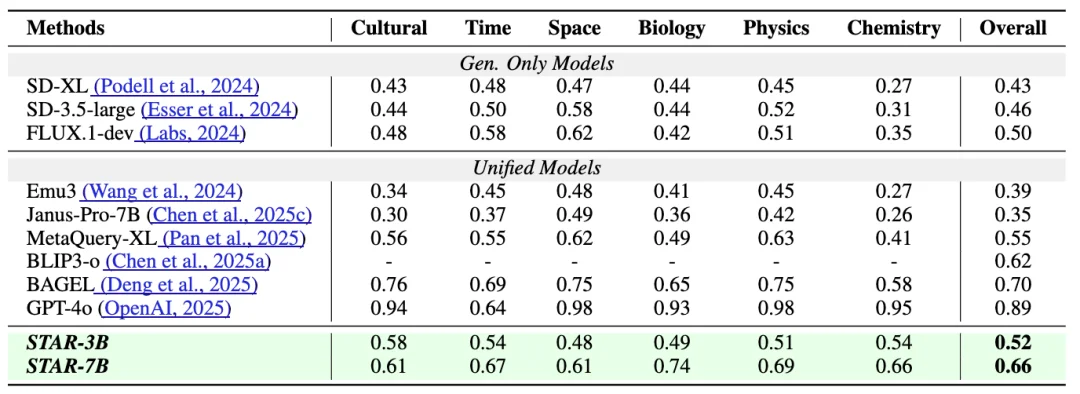
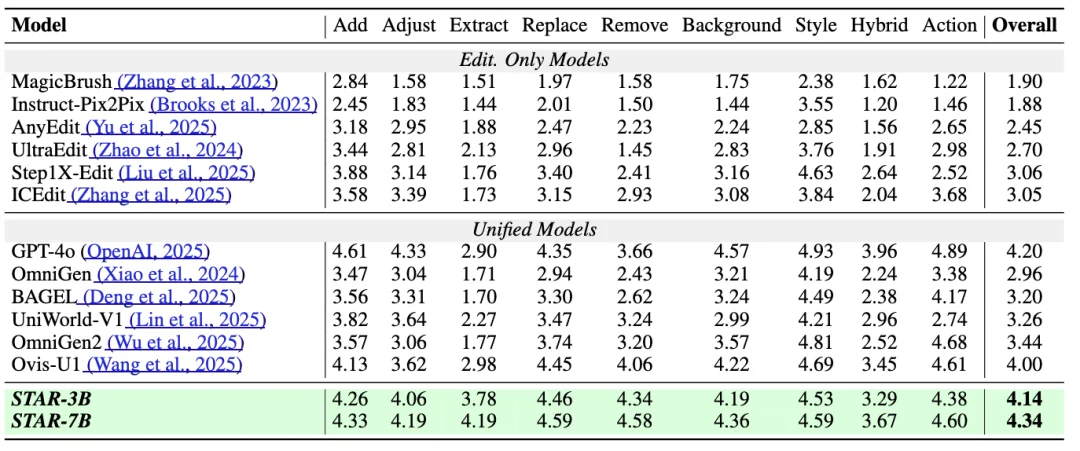
🔹 Editing Performance
| Benchmark | Metric | STAR-7B | Prior SOTA |
|---|---|---|---|
| ImgEdit | Overall (9 tasks) | 4.34 | 4.12 |
| Object Extraction | 4.19 | 3.95 | |
| Action Editing | 4.60 | 4.28 | |
| MagicBrush | CLIP-I (Semantic Consistency) | 0.934 | 0.891 |
| L1 Error (Pixel Fidelity) | 0.056 | 0.083 |

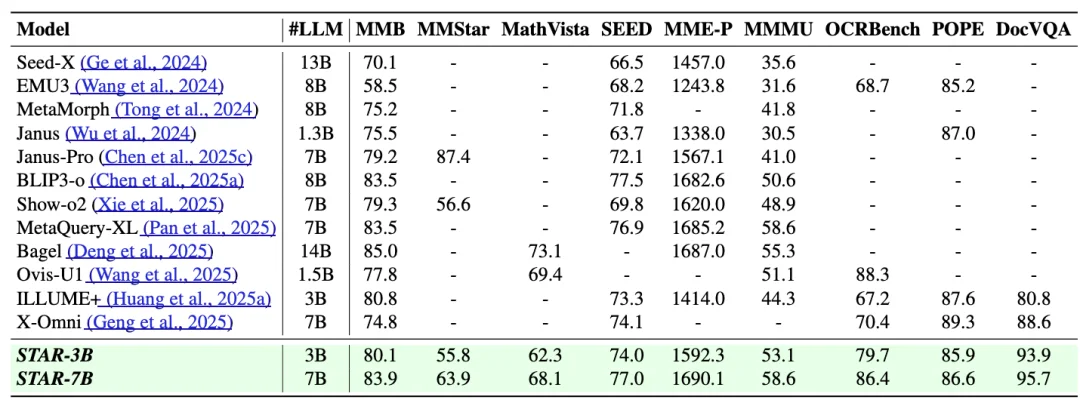
🔹 Understanding Integrity
Despite heavy generation focus, STAR maintains top-tier comprehension across 9 benchmarks — outperforming unified models like LLaVA-OneVision and InternVL.
🌐 Open Resources
- Paper: STAR: Stacked AutoRegressive Scheme for Unified Multimodal Learning
- Project Page: star-mm-ai.github.io
- Code: GitHub: MM-MVR/STAR
- Keywords: Unified Multimodal Learning · Stacked Autoregression · Task-Progressive Training
🔮 Future Directions
- Modality Expansion: Integrating video, 3D, and audio into the STAR framework
- Training Efficiency: Exploring joint optimization and lightweight stacking
- Reasoning Augmentation: Coupling implicit reasoning with external knowledge graphs or RL-based verification
- AGI Integration: Scaling STAR toward foundation-level cross-modal world modeling
STAR redefines scalability in multimodal AI — proving that understanding depth and generative power are not mutually exclusive, but multiplicatively synergistic.
Source: Machine Heart — Adapted and translated for global AI research audience.