Google Unveils Gemini 3.1 Flash Live for Real-Time Voice Agents
A new era of voice-first AI productivity has begun — where speaking replaces typing, and real-time multimodal interaction reshapes app development, design, and human-AI collaboration.
🚀 Breakthrough Launch: Gemini 3.1 Flash Live Goes Live
In a landmark release early March 27, Google officially launched Gemini 3.1 Flash Live — its highest-fidelity, low-latency audio and speech model — across three key platforms:
- ✅ Gemini App (consumer-facing mobile & desktop)
- ✅ Search Live (real-time multilingual search interface)
- ✅ Google AI Studio (developer preview with API access)
This isn’t just an incremental upgrade — it’s the foundation for true voice-native agents, engineered to understand tone, pace, pauses, background noise, and multi-turn context — all in real time.
⚡ Core Capabilities: Beyond Voice Recognition
🔁 Enhanced Real-Time Agent Intelligence
- 2× larger context window in Gemini Live — enabling richer memory and continuity across extended conversations.
- Support for real-time multimodal coding (“vibe coding”): Speak UI changes — “Make the mic bigger,” “Add yellow polka dots to the background,” “Switch to Pop Art style” — and watch the interface update instantly.
- Seamless cross-language switching mid-dialogue, e.g., transitioning from English to Spanish while preserving conversational flow and emotional context (as demonstrated with elderly users on Ato hardware).
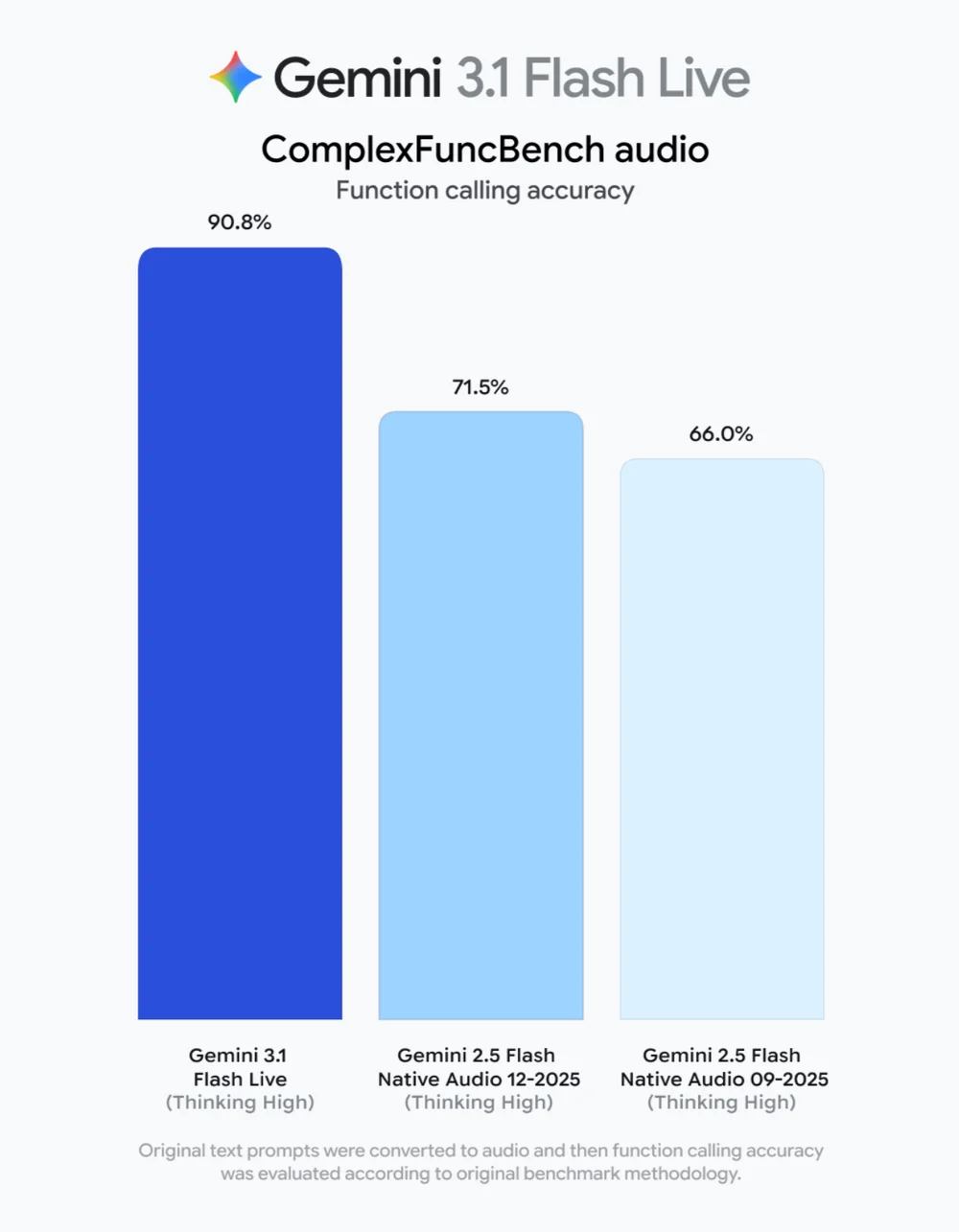
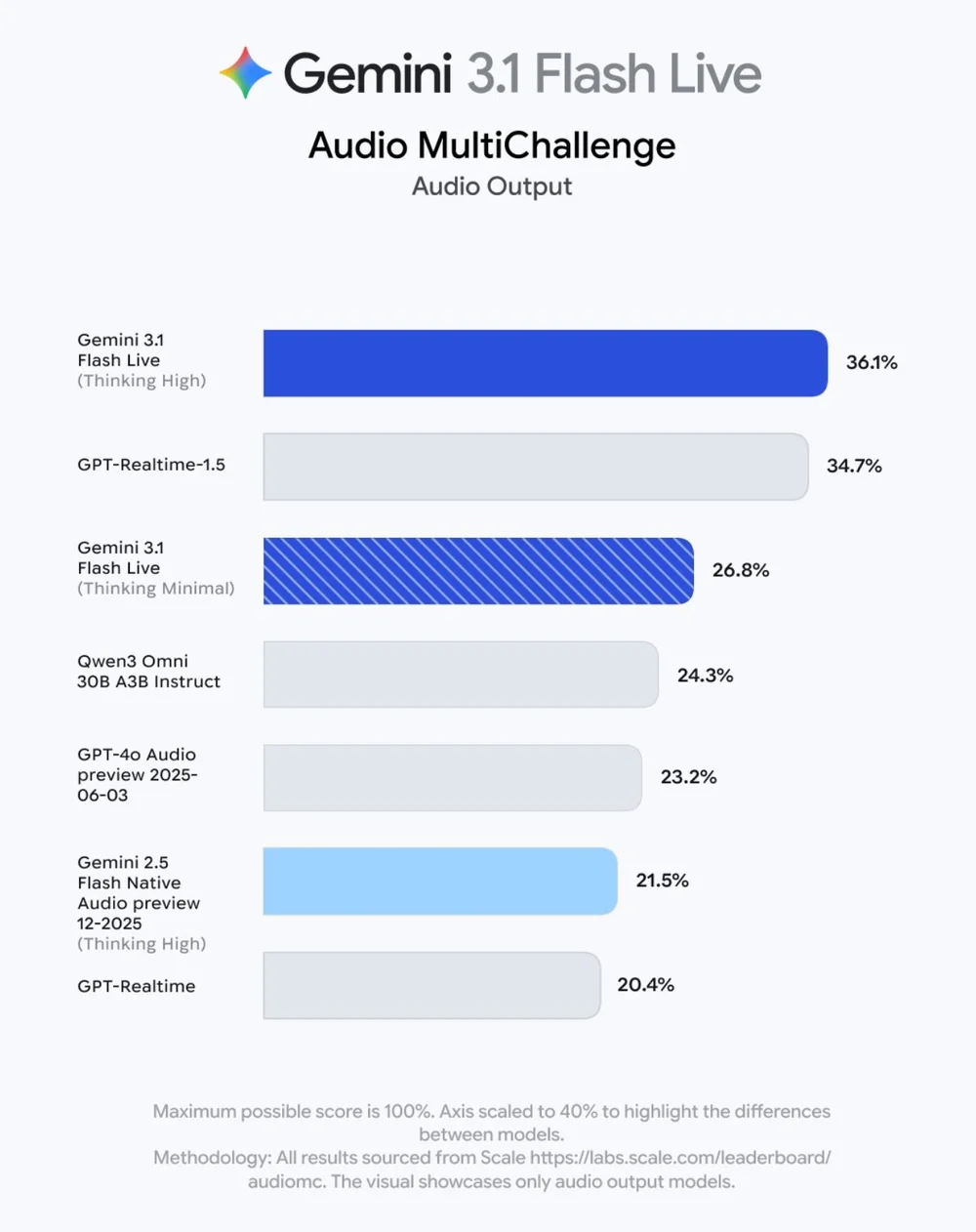
📊 Benchmark Leadership
| Benchmark | Gemini 3.1 Flash Live | GPT-Realtime-1.5 | Qwen3 Omni 30B | GPT-4o Audio Preview |
|---|---|---|---|---|
| ComplexFuncBench (Function Call Acc.) | 90.8% | 71.5% | 66.0% | — |
| Scale Audio MultiChallenge Score | 36.1% | 34.7% | 24.3% | 23.2% |
🧩 Three Production-Ready Use Cases
💻 Voice-Driven App Development (Vibe Coding)
Developers use natural speech inside Google AI Studio to iteratively refine UIs — adjusting layout, color, interactivity, and animation in one continuous session, mimicking live designer collaboration.
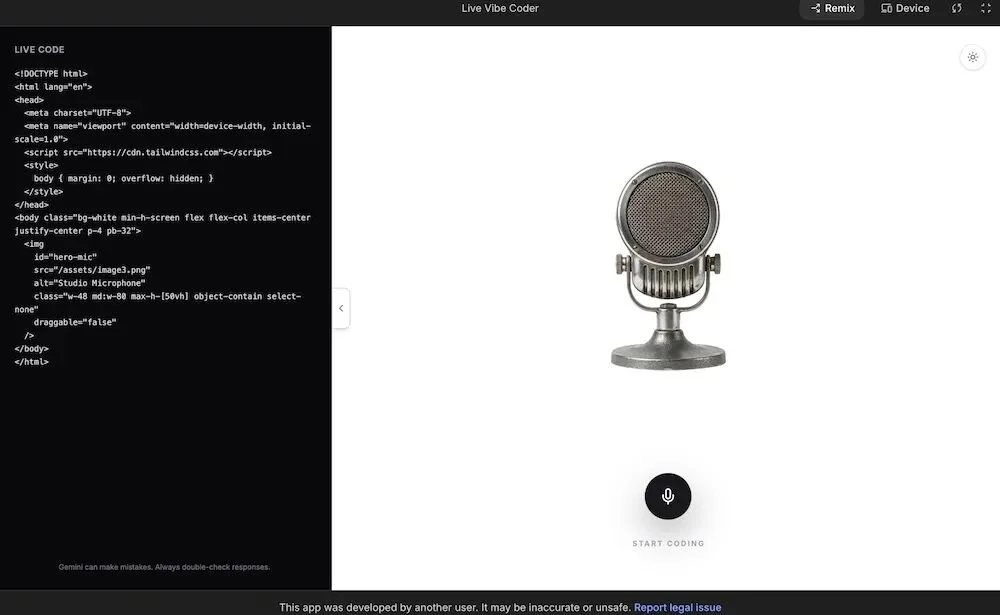
▲ Live Vibe Coder interface — fully interactive and responsive to spoken commands.
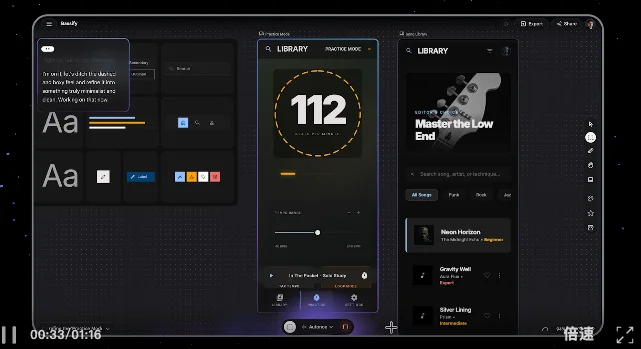
🎨 Design Collaboration in Stitch
Users command interface edits verbally: “Jump to practice mode → switch to song library → soften sharp borders → apply warm wooden palette.” Visual output updates instantaneously — no code required.
🌐 Multilingual Companion & Immersive Gaming
- Ato hardware demo: Real-time English ↔ Spanish switching during empathetic elder-care dialogues (e.g., “Just came home from the hospital — feeling tired” → adaptive, context-aware responses).
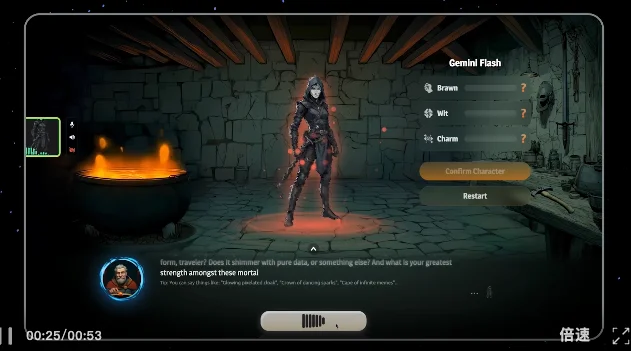
- RPG game Wit’s End: Voice-driven character roleplay — consistent persona, lore-aligned replies, and expressive vocal delivery — all grounded in world-building constraints.

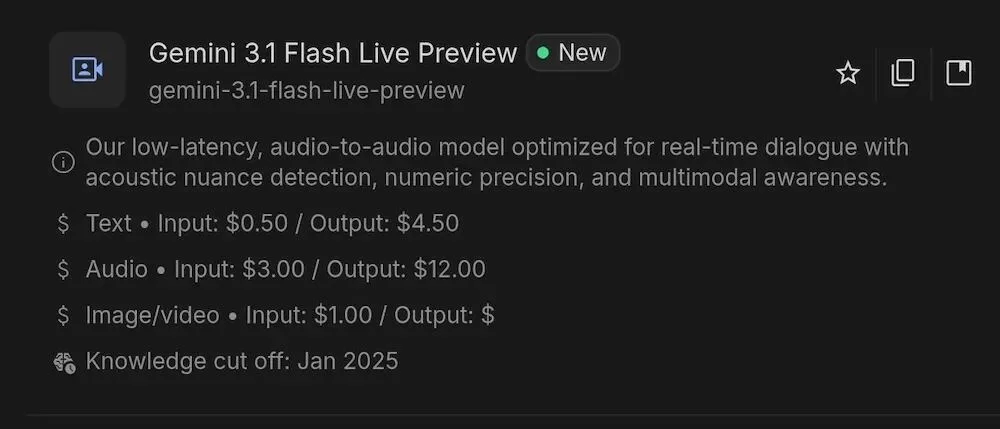
💰 Transparent Pricing & Developer Access
The official API pricing is now live:
| Input/Output Type | Cost per Unit |
|---|---|
| Text input | $0.50 / million tokens |
| Text output | $4.50 / million tokens |
| Audio input | $3.00 / minute |
| Audio output | $12.00 / minute |
✅ Supports multimodal input (audio + text + image) and tool-calling integrations.
🌍 Global Reach & Real-World Feedback
- Search Live supports real-time voice interactions in 200+ countries and languages.
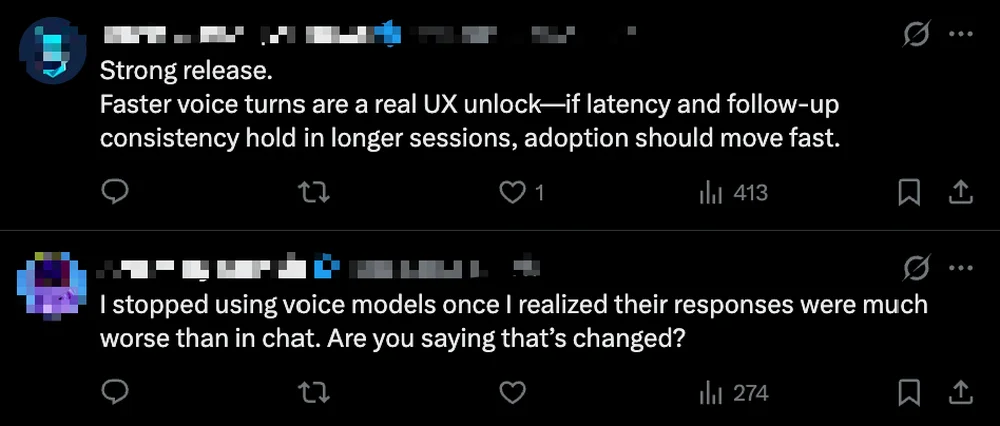
- Early adopters praise “dramatically reduced latency” and “breakthrough continuity in long-form dialogue” — calling it a “user experience inflection point.”
- Some developers remain cautious: “Voice quality still lags behind text — has that truly changed?”
- Initial testing reveals strong English fluency, but Chinese voice synthesis remains mechanical, with occasional conversation breaks — likely due to staged rollout (iOS/Android updates rolling out progressively).
🌐 Competitive Landscape: Global Race Heats Up
While Google pushes the frontier of full-stack voice agents, global competition intensifies:
- Domestic progress: Step-Audio R1.1 (Jieyue Xingchen) leads the Artificial Analysis Voice Reasoning Leaderboard with 96.4% accuracy, outperforming Grok, Gemini, and GPT-Realtime.
- Product divergence: Unlike China’s Doubao — optimized for expressive, humorous Chinese engagement — Google prioritizes robust capability expansion, especially in developer-centric voice workflows.
🏁 Conclusion: The Full-Stack Voice Agent Is Here
Gemini 3.1 Flash Live signals Google’s strategic shift: voice is no longer a front-end modality — it’s the core runtime layer for intelligent agents. From vibe coding and cross-lingual companionship to immersive gaming, this release delivers production-grade infrastructure for continuous, contextual, and collaborative voice interaction — setting a new benchmark for what “AI productivity” truly means.
Source: Original article by “Zhixi Dong” (Intelligence Things), republished via AITNT.