Google Launches Gemini Embedding 2: Unified Multimodal Vector Space
Breaking News — Google has officially launched Gemini Embedding 2 into General Availability (GA), marking the first native multimodal embedding model in the Gemini API suite. It maps text, images, video, audio, and PDFs into a single unified vector space, supporting over 100 languages.
🔍 A New Foundation for AI Retrieval
On May 1, Google for Developers announced the GA release with a deceptively quiet tweet:
“Now that Gemini Embedding 2 is GA, let’s explore what the model unlocks — from agentic multimodal RAG to visual search — as it maps text, images, video, audio, and documents into a unified embedding space.”

▲ Google for Developers official tweet announcing GA — viewed over 9,000 times
This isn’t just another LLM upgrade. It’s a foundational shift — moving multimodal understanding from the generation layer down to the retrieval infrastructure.
🌐 The “Universal Translator” Analogy
Google AI describes the model as a “universal translator”:
“Think of an embedding model as a ‘universal translator.’ It takes text, images, video, and audio data and turns them into a long string of numbers, like a unique digital fingerprint.”
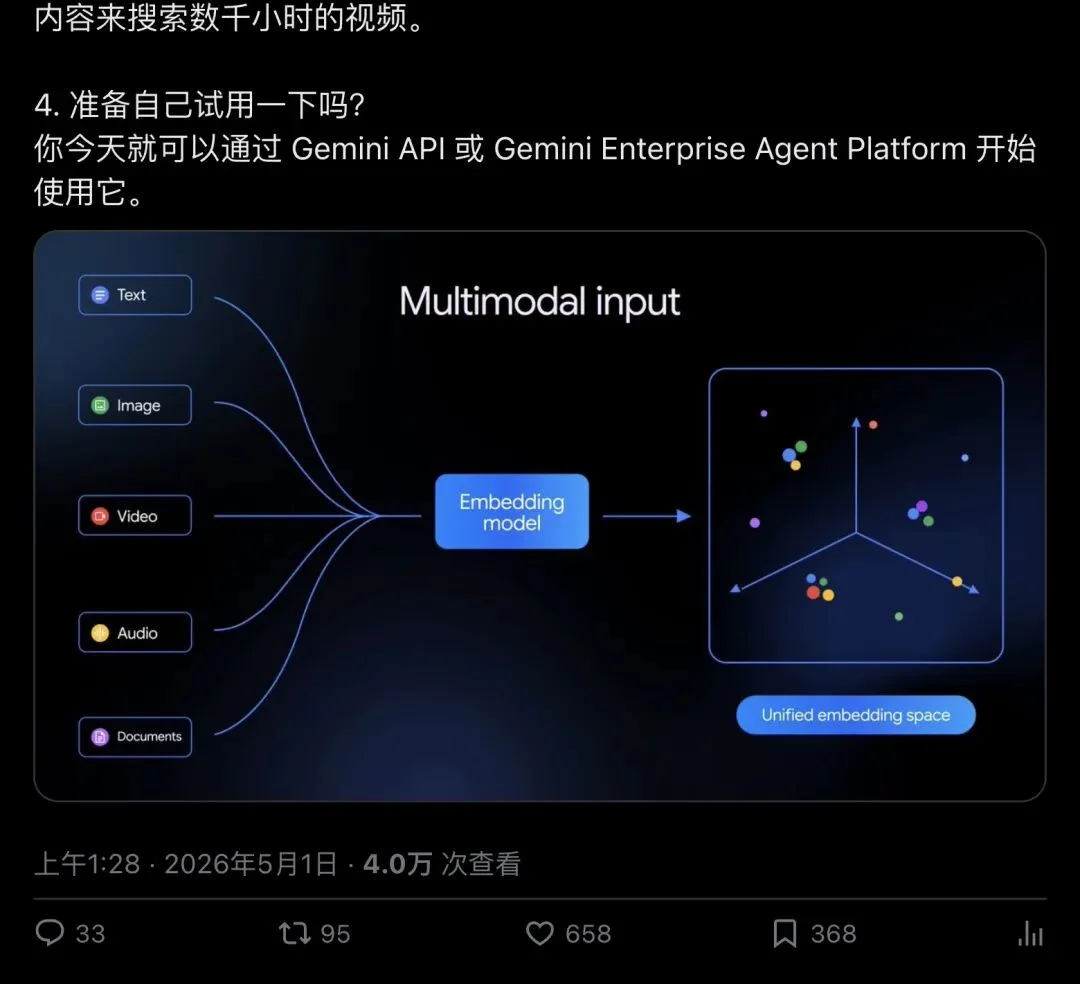
▲ Google AI’s科普-style post — nearly 40K views, 656+ likes
✅ What This Enables:
- Search a video using only a natural-language query
- Find identical or similar products via image upload
- Index mixed-modal content (PDF + chart + caption) in one pipeline
- Empower AI agents to retrieve evidence across text, images, audio, and video — all within the same semantic space
💡 Before: 4–5 separate encoding pipelines + complex alignment logic.
Now: One API call → one vector → cross-modal retrieval.
⚙️ Technical Specifications & Engineering Readiness
Gemini Embedding 2 is built for real-world deployment:
| Modality | Max Input |
|---|---|
| Text | 8,192 tokens |
| Images | Up to 6 images per request |
| Video | 120 seconds (keyframe-based) |
| Audio | 180 seconds (transcribed + embedded) |
| Documents | PDFs (text + layout-aware parsing) |
- Default output dimension:
3072— configurable viaoutput_dimensionalityto768/1536/3072 - Built on Matryoshka Representation Learning (MRL) — enabling dimensionality-aware scaling: smaller vectors retain semantic fidelity, slashing storage and latency costs.

▲ Official documentation page — includes code samples, dimension strategies, and multimodal integration guides
▲ Joint blog by Google DeepMind PM Min Choi & Distinguished Engineer Tom Duerig
📈 Real-World Impact: Three Verified Use Cases
🏛️ Harvey (Legal Tech)
- Use Case: Legal document retrieval & citation accuracy
- Result: +3% Recall@20 — critical for reducing misquotation risk in litigation.
🧠 Supermemory (Personal Knowledge Base)
- Use Case: Cross-modal memory recall (notes + screenshots + voice memos)
- Result: +40% Recall@1 — dramatically increases first-hit relevance.
👗 Nuuly (Fashion E-commerce)
- Use Case: Visual search for apparel inventory matching
- Result: Match@20 ↑ from 60% → 87%; overall recognition rate ↑ from 74% → >90%
▲ Google Developers Blog — showcasing agentic RAG, visual search, and engineering specs
🤖 Agentic Retrieval: The Hidden Agenda
The term “agentic retrieval” appears deliberately in Google’s seed tweet — signaling strategic alignment with the Gemini Enterprise Agent Platform.
Gemini Embedding 2 serves as the agent’s:
– 👁️ Eyes (understanding visuals),
– 👂 Ears (processing audio),
– 📄 Memory index (PDF + structured docs),
– 🔍 Cross-modal search engine (unified semantic space).
This eliminates siloed retrieval layers — enabling agents to autonomously gather, compare, and synthesize evidence across modalities.
🌐 Developer Community Reaction: Enthusiasm Meets Scrutiny
✅ Builder Validation
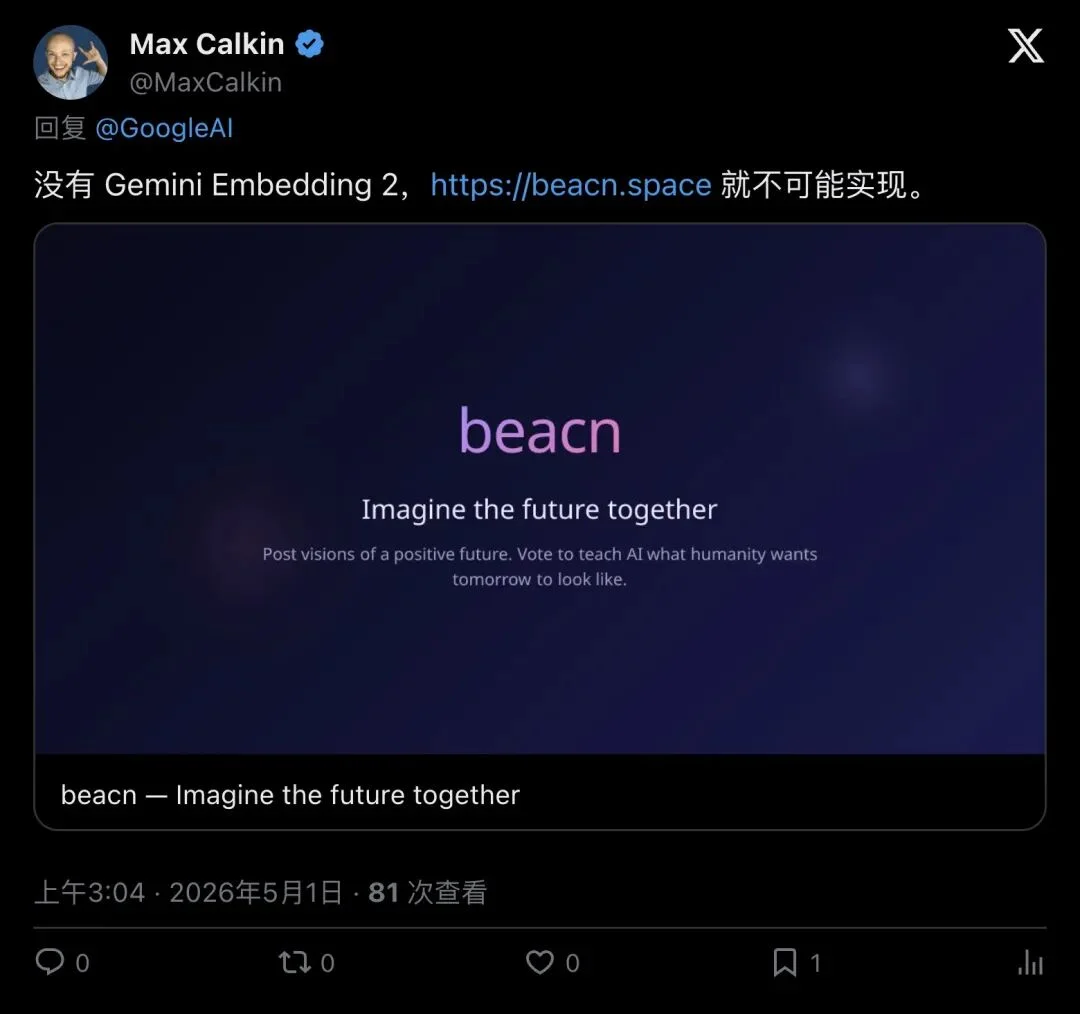
- Max Calkin (beacn.space): “Without Gemini Embedding 2, our product simply wouldn’t exist.”
⚠️ Security Concerns
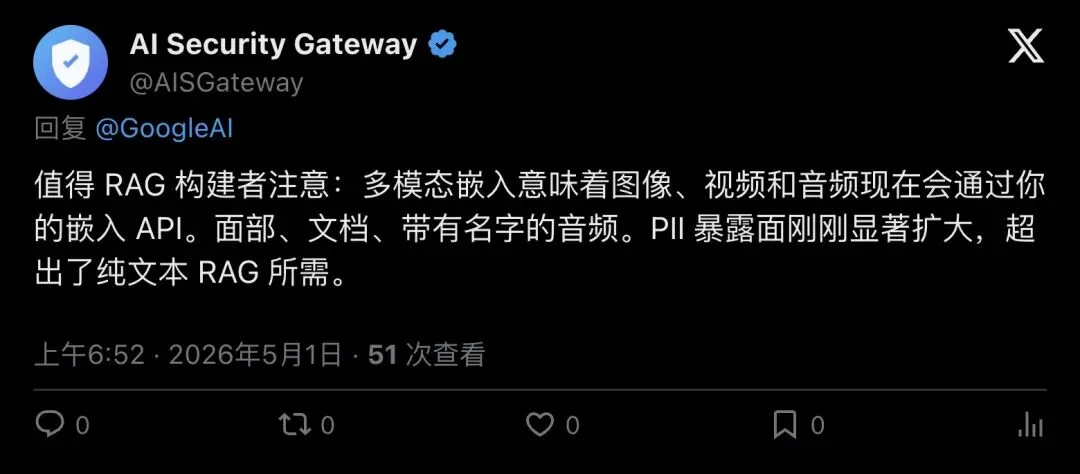
- AI Security Gateway: “PII exposure surface expands significantly — faces in images, names in audio, sensitive layouts in PDFs now flow through the same embedding pipeline.”
🧪 Real-World Robustness Question
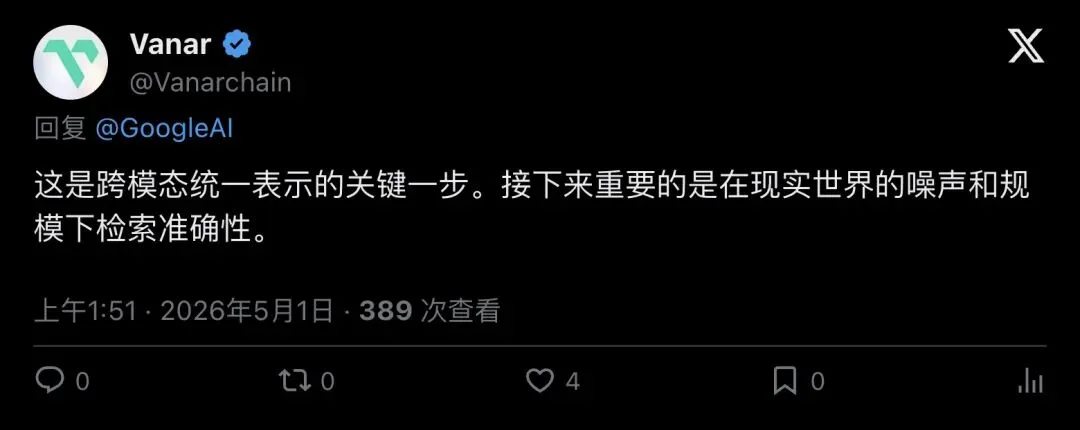
- Vanar: “Crucially, does retrieval accuracy hold up under real-world noise, scale, and domain drift?”
💬 Hacker News Highlights
- “This is colossal.” — jeanloolz (36+ upvotes)
- Comparison to Qwen’s open multimodal embeddings, citing steerability & control advantages
- Immediate pricing and scalability questions from engineering leads
⚠️ Operational Realities: Migration & Governance
🔄 Index Rebuild Overhead
Switching embedding models requires full vector database re-indexing — demanding shadow testing, A/B evaluation, and phased rollout.
🛡️ Expanded Data Governance Surface
Multi-modal inputs introduce new PII vectors: facial biometrics (images), voiceprints (audio), document metadata (PDFs). Legacy text-only compliance frameworks are insufficient.
🏁 Conclusion: The Infrastructural Turn in Multimodal AI
Gemini Embedding 2 marks a pivotal transition:
🔹 From multimodal demos → production-grade retrieval infrastructure
🔹 From modality-specific encoders → unified semantic coordinates
🔹 From LLM-as-answerer → agent-as-autonomous-researcher
The race for AI’s retrieval stack has begun — and while Google pushes its API-first enterprise platform, open alternatives (Qwen, etc.) are rapidly maturing. The battle isn’t just about model quality anymore — it’s about ownership, control, cost, and trust in the foundation layer.
Article adapted from WeChat public account “Guigong Shuoshi”.