Gemini Embedding 2 Goes GA: Unified Multimodal Vector Space
Google has officially launched Gemini Embedding 2 into General Availability (GA) — the first natively multimodal embedding model in the Gemini API suite. It maps text, images, video, audio, and PDFs into a single, shared vector space, supporting over 100 languages.

▲ Google for Developers official GA announcement — 9,000+ views
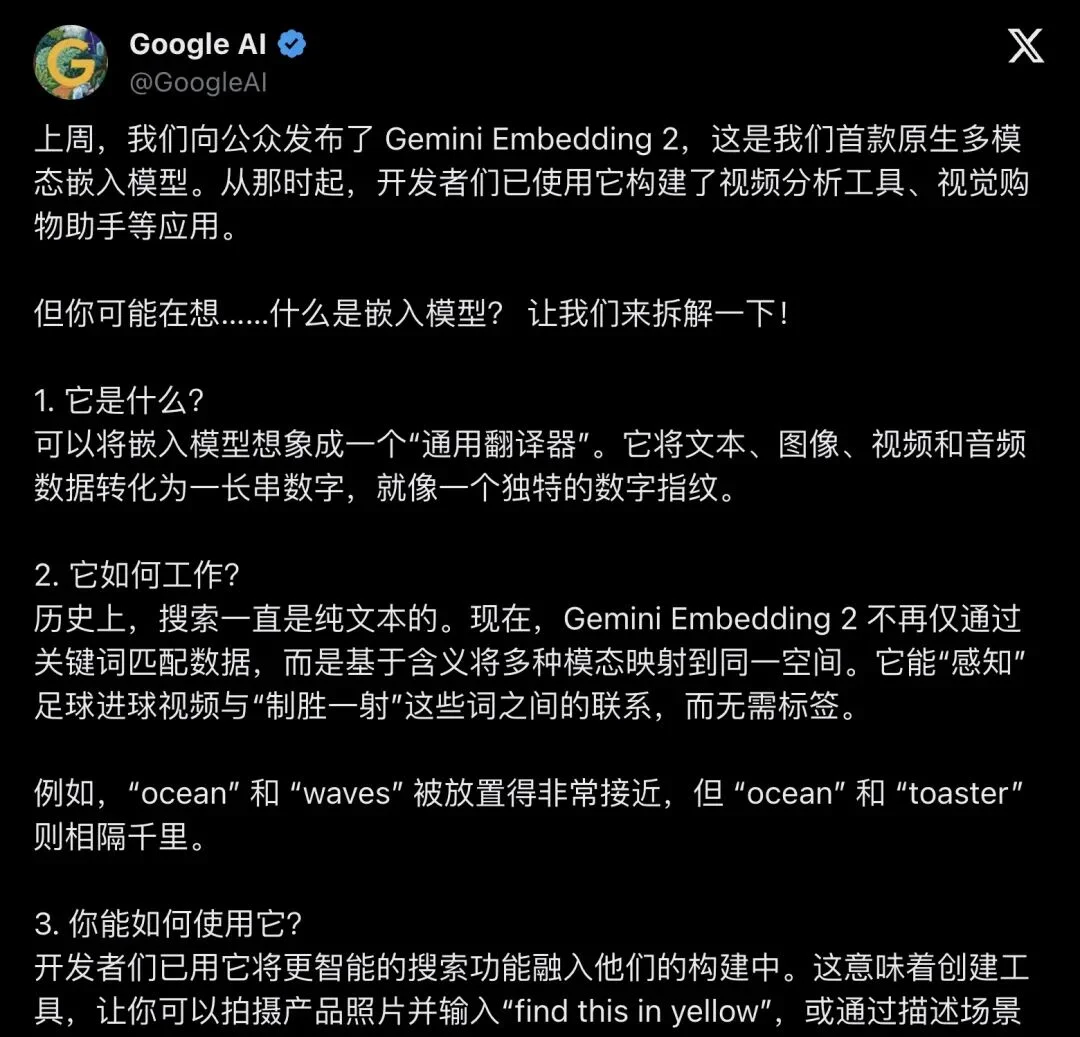
▲ Google AI’s intuitive “universal translator” analogy — nearly 40K views, 656 likes
🔑 Core Innovation: One Space, All Modalities
Gemini Embedding 2 transcends traditional unimodal encoders. Instead of separate pipelines for text, vision, or audio, it delivers native interleaved input understanding: you can pass mixed modalities — e.g., an image + descriptive text — in a single API call, and receive one cohesive embedding vector.
This isn’t just “multimodal awareness” — it’s multimodal retrieval infrastructure, built from the ground up.
✅ Key Capabilities
- Cross-modal search: Search video using natural language; find products via image upload.
- Unified indexing: Index PDFs, screenshots, meeting transcripts, and product videos together.
- Agentic recall: Empower AI agents to autonomously retrieve evidence across documents, charts, voice notes, and screenshots — all within one semantic coordinate system.
⚙️ Technical Specifications
| Input Type | Limit |
|---|---|
| Text | Up to 8,192 tokens |
| Images | Up to 6 images per request |
| Video | Up to 120 seconds (keyframe-based) |
| Audio | Up to 180 seconds (transcribed + embedded) |
| Full-document embedding (text + layout-aware features) |
- Output dimensionality: Default 3,072, with configurable truncation (768 / 1,536 / 3,072) via
output_dimensionality. - Underlying technique: Matryoshka Representation Learning (MRL) — enables efficient, scalable retrieval without full-dimension overhead.
▲ Gemini API Embeddings docs: code samples, dimension strategies & multimodal integration guide
🚀 Real-World Impact: Three Verified Use Cases
📜 Harvey (Legal Tech)
- Use case: Legal document retrieval & precedent matching
- Result: +3% Recall@20 — critical for reducing citation errors in high-stakes litigation.
💾 Supermemory (AI Memory Platform)
- Use case: Personal knowledge base search across notes, recordings, and screenshots
- Result: +40% Recall@1 — meaning the top result is correct nearly twice as often.
👗 Nuuly (Fashion E-commerce)
- Use case: Visual search for rental apparel inventory
- Result: Match@20 ↑ from 60% → 87%; overall recognition rate surged from 74% → >90%.
▲ Google Developers Blog: real-world application specs & architecture patterns
🤖 Strategic Implication: Powering Agentic Retrieval
The term “agentic retrieval” — highlighted in Google’s seed tweet — signals a paradigm shift:
🧠 Agents no longer rely solely on textual context. Now they can:
– “See” charts and UI screenshots,
– “Hear” meeting summaries or customer calls,
– “Read” scanned contracts or annotated PDFs,
– And unify all evidence into one searchable semantic index.
This positions Gemini Embedding 2 as the foundational retrieval layer for the Gemini Enterprise Agent Platform, enabling end-to-end agentic workflows — not just chat.
⚖️ Community Response: Enthusiasm Meets Scrutiny
✅ Builder Perspective
- Max Calkin (beacn.space): “Without Gemini Embedding 2, our product simply wouldn’t exist.”
⚠️ Security & Governance Concerns
- AI Security Gateway: Warns of expanded PII surface — facial data, voice biometrics, and sensitive document visuals now flow through the same embedding pipeline.
- Vanar: Highlights the need for real-world robustness testing under noise, scale, and domain drift.
🌐 Hacker News Debate
- jeanloolz: “This is colossal.” — praises format coverage but notes context window constraints.
- Grimblewald: Compares with open alternatives like Qwen’s multimodal embeddings, questioning value vs. control and pricing transparency.
⚠️ Operational Realities: Migration & Compliance
🔄 Migration Cost
- Switching embedding models requires full vector index rebuild — non-trivial for production-scale knowledge bases.
- Requires phased rollout: shadow testing, A/B evaluation, and gradual cutover.
🛡️ Data Governance Expansion
- Multi-modal inputs dramatically increase compliance scope:
- Images → facial recognition & biometric PII,
- Audio → speaker identity & voiceprints,
- Video → scene context & ambient data,
- PDFs → redaction integrity & metadata leakage.
- Legacy text-only governance policies are insufficient.
🏁 Final Thought: The Retrieval Infrastructure War Has Begun
Gemini Embedding 2 marks more than an API update — it’s Google’s declaration that multimodal retrieval is now core infrastructure, not a demo feature.
As closed APIs compete with open alternatives (Qwen, Jina, OpenCLIP), the battle lines are drawn around:
– Control (hosted vs. self-deployable),
– Cost efficiency (MRL-enabled dimension tuning),
– Trust & auditability (PII handling, explainability, compliance).
The ceiling for AI applications is no longer capped by modality silos — but by how wisely we build, govern, and scale the foundation beneath them.
Article originally published by “Guigong Shuoshi”.