daVinci-MagiHuman: Open-Source Audiovisual Foundation Model
Architecture-level breakthrough in open-source multimodal generation
Video generation stands at the forefront of generative AI — yet synchronized audiovisual synthesis remains a critical unsolved challenge in the open-source community. Three key limitations have persisted:
- Audio-Visual Desynchronization: Semantic alignment between video and audio is often imprecise.
- Architectural Complexity: Existing approaches either treat audio as subordinate or duplicate backbone networks — doubling parameter count and hindering inference optimization.
- Slow Generation Speed: Complex, non-unified architectures lead to inefficient inference, limiting real-time interactivity.
Today, a joint effort by Shanghai SII’s GAIR Lab (led by Dr. Pengfei Liu) and Sand.ai (founded by Dr. Yue Cao, Marr Prize winner) introduces daVinci-MagiHuman — an open-source, 演绎级 (performance-grade) human-centric audiovisual foundation model that overcomes all three barriers.

Key Specifications
- Model Type: Single-stream Transformer (15B parameters)
- Modalities Supported: Text + Video + Audio (unified joint modeling)
- Inference Speed: 2 seconds for 5-second, 256p video on a single H100 GPU
- Languages: Native support for Mandarin (Putonghua & Cantonese), English, Japanese, Korean, German, French
- Open Release: Full stack — base model, super-resolution module, and optimized inference code
📦 Public Resources
- Code Repository: https://github.com/GAIR-NLP/daVinci-MagiHuman
- Model Weights: https://huggingface.co/GAIR/daVinci-MagiHuman
- Live Demo: https://huggingface.co/spaces/SII-GAIR/daVinci-MagiHuman
Research Team Spotlight
🔹 Shanghai SII GAIR Lab
A collaborative research unit co-established by top-tier universities, industry leaders, and R&D institutes. Under Dr. Pengfei Liu, GAIR focuses on cutting-edge generative AI — including multimodal video foundation models, LLM pretraining, and agentic systems. Its research lineage includes:
- Anole: First native diffusion-free multimodal model
- Thinking with Generated Images: A novel visual reasoning paradigm
- LiveTalk: Real-time interactive multimodal agent
- Digital Gene: Framework for digital world understanding & simulation
- Recent flagship works:
daVinci-MagiHuman,Data Darwinism,daVinci-Agency,daVinci-Dev

🔹 Sand.ai
Founded by Dr. Yue Cao, Sand.ai pioneers video-generation AGI. Notable releases include:
- Magi-1: World’s first autoregressive video generation model
- GAGA-1: “AI Actor” model excelling in physical consistency and native audio-video synchronization
Technical Innovation: Unified Single-Stream Transformer
Rather than relying on multi-stream backbones or cross-attention modules, daVinci-MagiHuman embeds text, video, and audio tokens into a shared latent space, processed end-to-end by a single 15B-parameter Transformer denoising network.
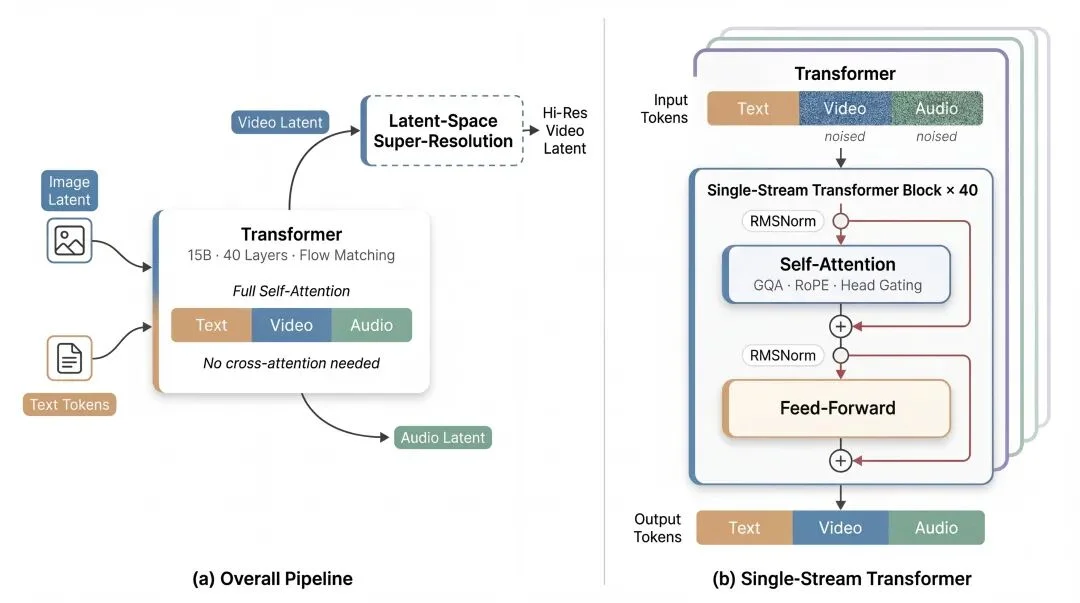
Core Design Principles
- Sandwich Backbone: Modality-specific parameters only at input/output layers; deep middle layers are fully shared — balancing specialization and fusion.
- Timestep-Free Conditioning: Eliminates explicit timestep embedding; denoising state is inferred directly from noisy latents.
- Attention-Head Gating: Per-head gating improves numerical stability and expressive capacity of attention.
- Unified Conditional Interface: Text prompts, reference audio, and visual cues all enter the same backbone via standardized projection — no task-specific fusion modules.
Four-Tier Inference Optimization Stack
To achieve real-time performance without compromising quality:
1. Latent-Space Super-Resolution
A two-stage pipeline: low-res base model → latent-space refinement. Uses trilinear interpolation + light re-noising — avoids costly VAE encode/decode cycles. Critically, audio latents remain in the loop during super-resolution, preserving lip-sync fidelity.
2. Turbo VAE Decoder
Replaces Wan2.2’s heavy decoder with a lightweight Turbo VAE — significantly reducing decode latency on the critical path.
3. Full-Graph PyTorch Compilation
Integrated MagiCompiler, a custom graph-level compiler enabling:
– Cross-layer operator fusion
– Reduced distributed communication overhead
– ~1.2× speedup on H100
4. DMD-2 Distillation
Distills the denoiser to require only 8 denoising steps, matching full 20-step quality while accelerating inference.
Benchmark Performance: Outperforming Open SOTA
Evaluated against leading open models: LTX-2.3, Ovi 1.1, and MoVA.






✅ Subjective Evaluation (Human Blind Test)
- Dataset: 100 diverse text-to-audiovisual samples
- Metric: Multi-dimensional blind scoring (lip sync, expressiveness, naturalness)
- Result: 70.5% win rate vs. LTX-2.3 & Ovi 1.1
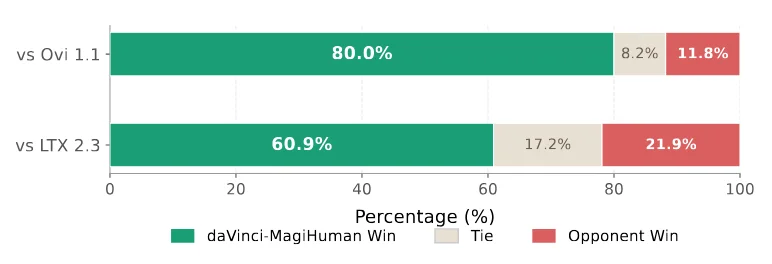
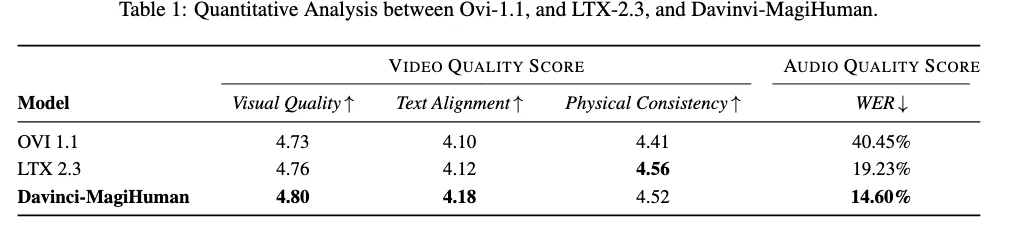
✅ Objective Benchmarks
| Metric | daVinci-MagiHuman | LTX-2.3 | Ovi 1.1 |
|---|---|---|---|
| Visual Quality (VideoScore2) | ✓ Best | △ | ✗ |
| Text Alignment (VideoScore2) | ✓ Best | △ | ✗ |
| Physical Consistency (VideoScore2) | ≈ LTX-2.3 | ✓ | ✗ |
| Audio WER (TalkVid-Bench) | ✓ Best | ✗ | ✗ |
Conclusion & Vision
daVinci-MagiHuman delivers a complete, production-ready open-source stack — not just a model, but a system: base generator, latent super-resolver, and compiled inference engine. By unifying modalities under one streamlined architecture and optimizing every layer of the stack, it lowers the barrier for developing high-fidelity, real-time audiovisual agents.
This release represents a leap toward truly plug-and-play, performant multimodal AI — empowering researchers, developers, and creators to build next-generation embodied agents, digital humans, and immersive media applications.
Article adapted from “Ji Qi Zhi Xing” (Machine Heart), edited by Machine Heart Editorial Team.