Code as the Universal Agent Harness
A landmark survey by UIUC, Meta, and Stanford reveals how executable code unifies AI coding assistants, GUI agents, robotics, and scientific discovery.

The Core Insight: Code Is Not Just Output — It’s the Operational Backbone
This 102-page, 478-reference survey reframes a fundamental question: What is the shared execution substrate that binds Claude Code, autonomous robots, OS-level agents, and scientific AI systems?
The answer is not infrastructure or APIs — it’s code itself: dynamically generated, executed, inspected, modified, and shared intermediate artifacts — such as Plan.md, Skills.md, validation scripts, and behavioral trees.
Unlike static model weights or ephemeral chat histories, code provides three irreplaceable properties:
- ✅ Executable: Runs deterministically on real hardware or sandboxes, yielding objective outcomes.
- ✅ Inspectable: Produces traceable logs, stack traces, errors, and runtime metrics.
- ✅ Stateful: Persists progress via file systems, databases, Git repositories, and memory-mapped objects.
These traits make code the only medium capable of bridging long-horizon reasoning, physical action, environmental modeling, and multi-agent consensus.
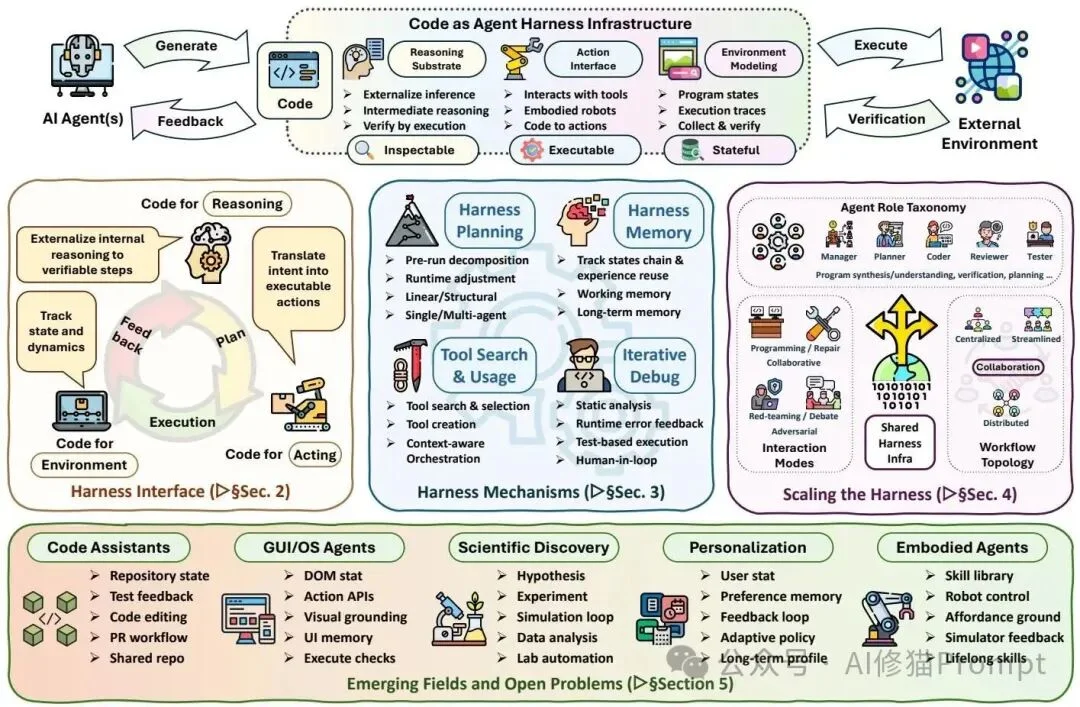
The survey proposes a unified three-layer architecture for code-centric agent systems.
Layer 1: Harness Interface — Code as Universal Bridge
Code serves as the foundational interface between LLMs and reality — enabling precise grounding across three domains:
🔹 Code for Reasoning
- Programmatic Delegation: Models generate Python scripts (not final answers) for external interpreters — decoupling logic from computation.
- Formal Verification: Integration with Lean/Isabelle enables machine-checked proofs — critical for math, security, and safety-critical code.
- Iterative Execution Loops: “Generate → Run → Observe Error → Revise” creates self-correcting, trajectory-guided reasoning.
🔹 Code for Acting
- Constrained Skill Invocation: Agents call pre-verified, physics-aware code modules (e.g., SayCan), avoiding unsafe raw control signals.
- Behavior Tree Generation: Full procedural scripts (with loops, conditionals) govern robotic motion or GUI navigation.
- Lifelong Skill Accumulation: Successful solutions are auto-encapsulated into reusable functions — building persistent skill libraries (e.g., Voyager).
🔹 Code for Environment Modeling
- Structured World Representations: DOM trees, class hierarchies, and spatial graphs encode environment semantics more precisely than natural language.
- Execution-Driven State Inference: Logs and test outcomes train predictive models of environment dynamics.
- Verifiable Micro-Worlds: Unit tests, mocks, and sandboxed environments provide objective correctness criteria.
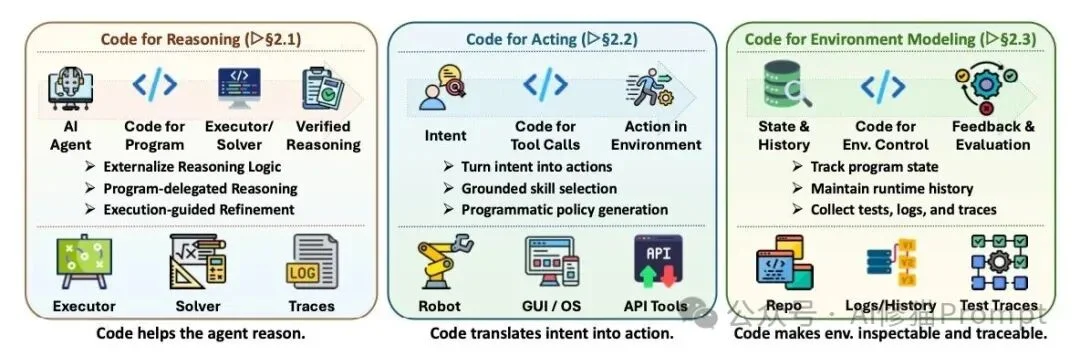
How code mediates reasoning, action, and environment awareness.
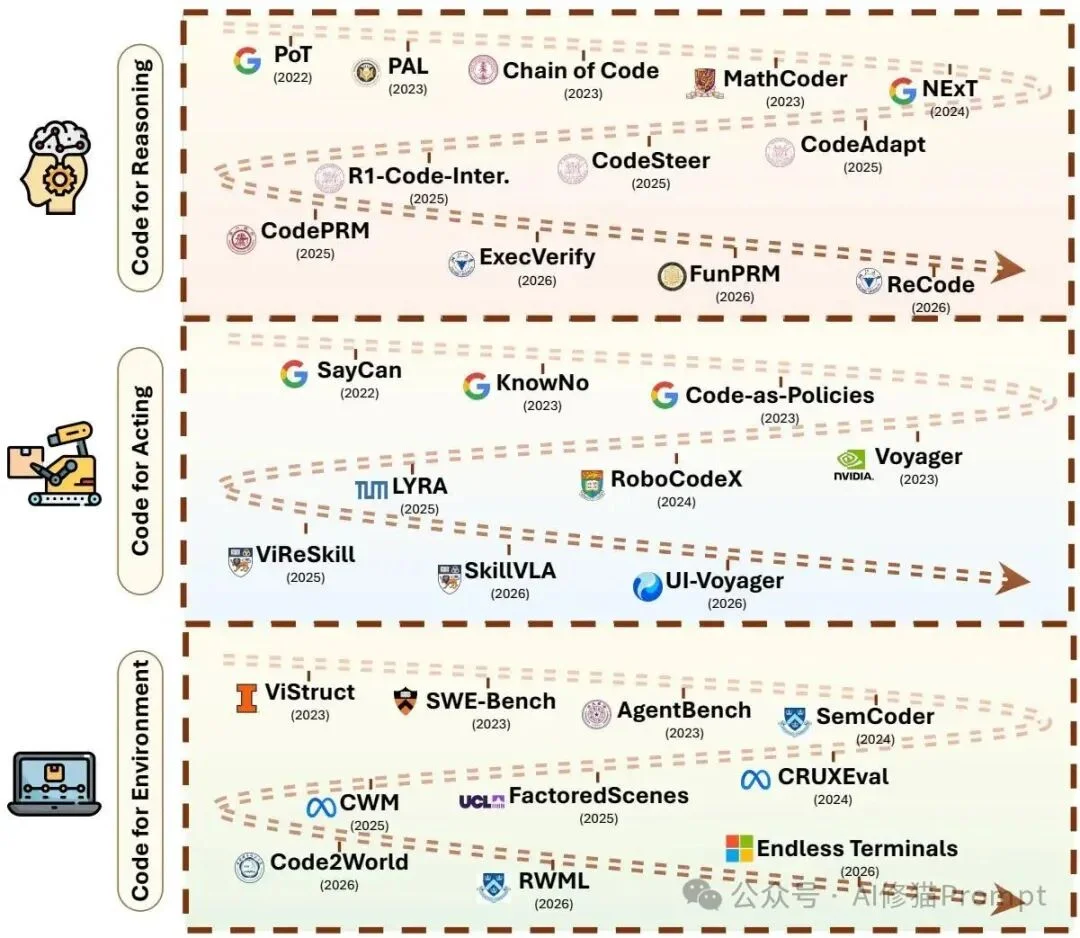
From program-assisted reasoning to robot control, GUI automation, and software engineering evaluation.
Layer 2: Harness Mechanisms — Ensuring Robust Long-Horizon Execution
To survive hours- or days-long tasks, agents require five tightly coupled mechanisms — all orchestrated around code:
🧭 Planning Mechanisms
| Type | Description | Example |
|---|---|---|
| Linear Decomposition | Task → step-by-step PLAN.md → sequential code generation |
SWE-agent GitHub issue resolution |
| Structure-Aware Planning | Leverages AST/class dependency graphs to prioritize safe edits | Codebase refactoring with impact analysis |
| Search-Based Planning | Uses MCTS to explore & backtrack through code generation branches | Debugging complex race conditions |
| Workflow Orchestration | Pipeline stages (retrieve → plan → code → test → validate) managed by system scheduler | CI/CD-integrated agent pipelines |
🧠 Memory & Context Engineering
- Working Memory: Strictly scoped to current file + recent error logs — prevents context dilution.
- Semantic Memory: RAG over codebases retrieves relevant classes, APIs, and docs on-demand.
- Experiential Memory: Structured bug-fix patterns and patch templates enable cross-task reuse.
- Context Compression: Logs auto-summarized or offloaded to files; only key evidence retained in prompt.
⚙️ Tool Use
- Knowledge Tools: API calls, documentation searchers, and knowledge bases.
- Interaction Tools: Shell executors, file I/O, repo navigators, and browser automation (Playwright).
- Verification Tools: Linters, type checkers, unit test runners — providing deterministic feedback.
- Workflow Tools: Orchestrators handling retries, fallbacks, and tool chaining.
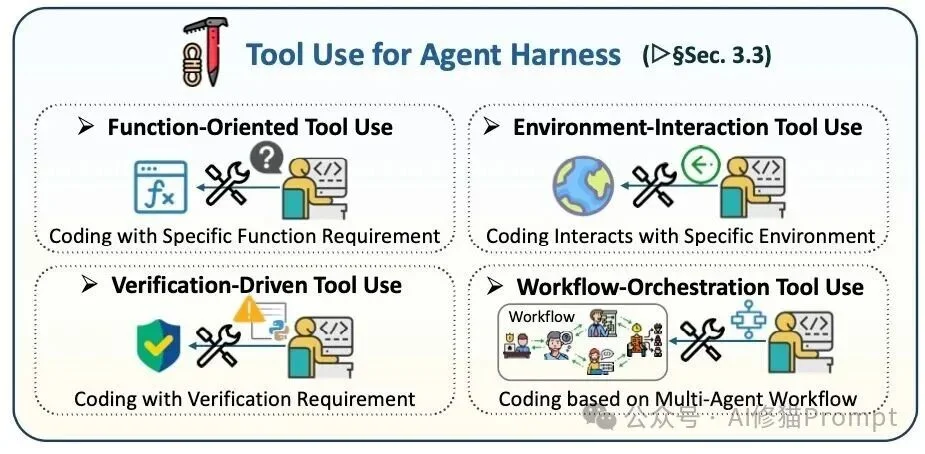
Tools span function calling, terminal access, sandboxing, verification, and workflow control.
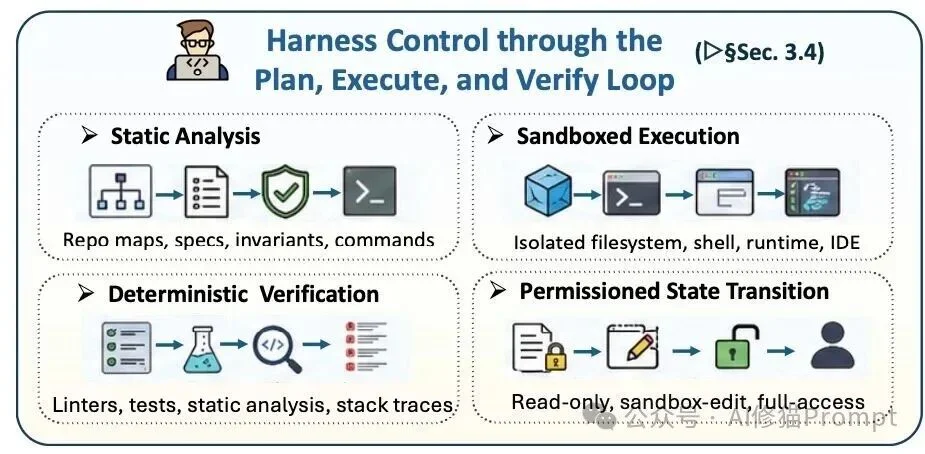
🔄 Plan-Execute-Verify (PEV) Loop
A cybernetic control framework ensuring reliability:
– Plan: Translate user intent into an explicit scope contract (e.g., “modify auth.py to add OAuth2 support”).
– Execute: Run only in isolated, permission-graded sandboxes — no host leakage.
– Verify: Combine static analysis (type safety) + dynamic testing (runtime behavior) + human-in-the-loop gating for high-risk ops.
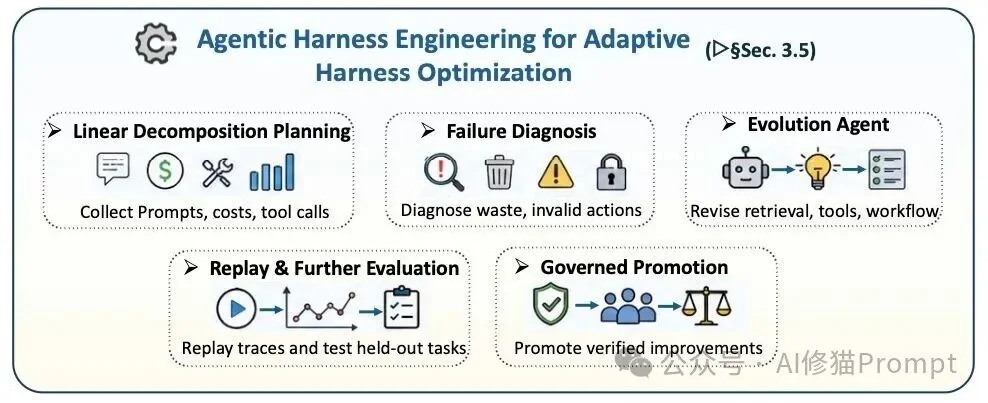
🛠️ Adaptive Harness Engineering (Novel Contribution)
The paper introduces self-optimizing scaffolds: treating prompts, retrieval strategies, tool descriptions, validators, and workflows as learnable, measurable, and governable assets.
– Deep Telemetry: Tracks token usage, latency, tool success rates, and full execution traces.
– Evolution Agent: A meta-agent analyzes telemetry to autonomously refine prompts, update sandboxes, or reconfigure verifiers — under governance constraints.
Layer 3: Multi-Agent Extension — Code as Shared Truth
When single agents hit scalability limits, code becomes the objective, versioned, verifiable substrate for collaboration — replacing fragile “chat-based consensus” with shared program state.
👥 Role Specialization
| Role | Responsibility | Key Artifact |
|---|---|---|
| Coder | Implements logic | feature.py |
| Tester | Generates adversarial inputs | test_edge_cases.py |
| Reviewer | Validates architecture & style | review_comments.md |
| Executor | Runs code, collects logs | execution_trace.json |
| Manager | Orchestrates workflow & deadlines | workflow_schedule.yaml |
💬 Interaction Modes
- Collaborative Synthesis: Pair programming — one navigates, one implements.
- Critique & Repair: Tester finds bugs → Coder fixes → Executor verifies.
- Adversarial Validation: Fuzzing tools crash code → logs feed back to Coder.
- Reasoning Debate: Multiple agents argue design trade-offs until convergence.
🌐 Shared Program State — The Critical Innovation
“Consensus must be objective — not just ‘I agree.’ It must mean: all tests pass, linters silent, performance targets met.”
Shared state is enforced via:
– Git repositories (immutable history + PR reviews)
– Blackboard architectures (in-memory shared objects)
– Full execution contexts (serialized environments)
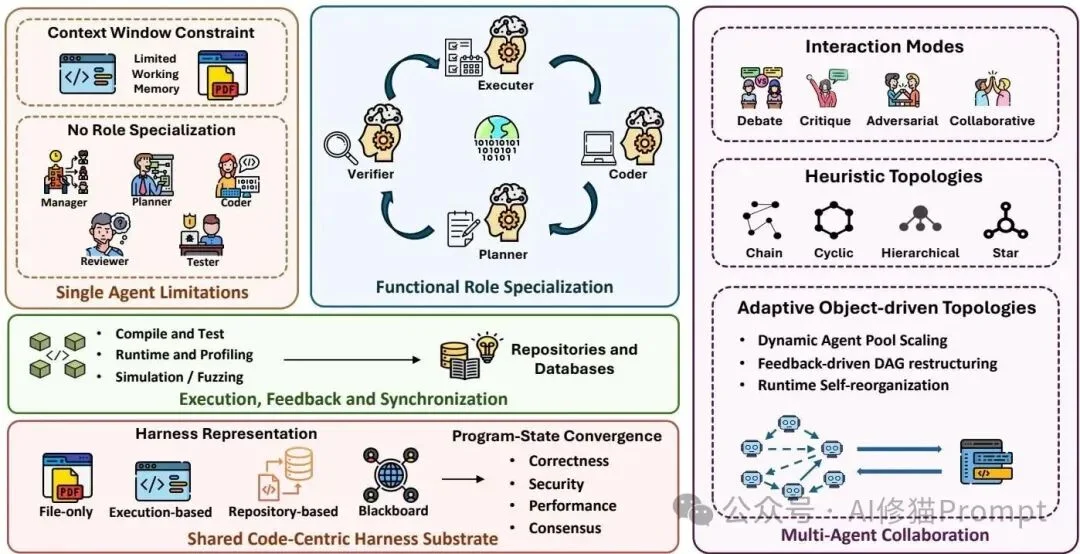
Multi-agent coordination grounded in shared, verifiable code state.
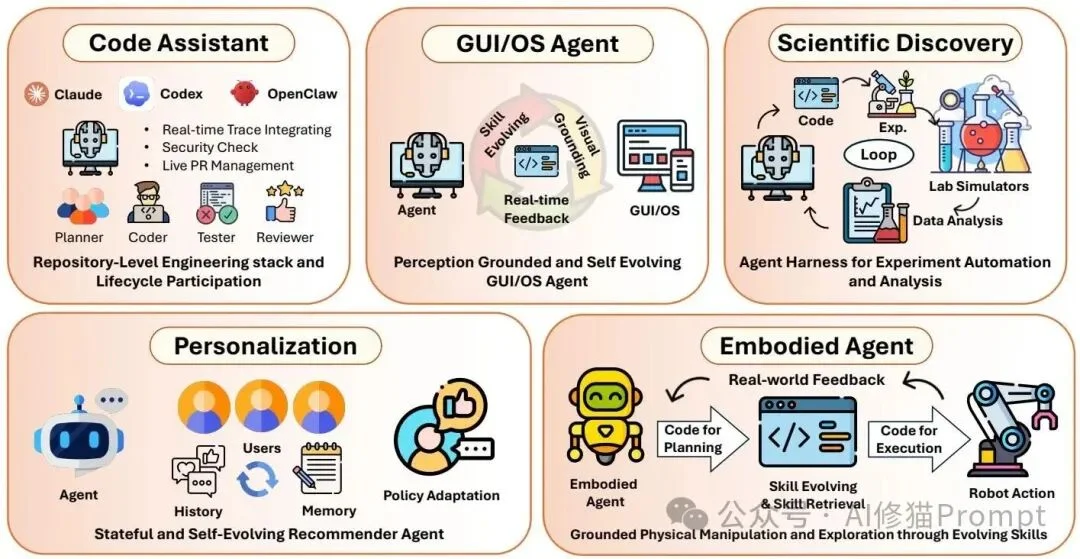
Real-World Applications: From Code to Physical World
| Domain | How Code Harness Enables It | Example System |
|---|---|---|
| AI Programming Assistants | Sandboxed execution + Git + test frameworks = autonomous PR submission | SWE-agent, OpenHands |
| GUI/OS Agents | DOM/Accessibility Tree parsing → Playwright/Python automation scripts | Desktop Copilot, Auto-GUI |
| Scientific Discovery | End-to-end code pipeline: literature → hypothesis → simulation → robot control → data analysis | AI Scientist |
| Personalization Engines | User feedback → auto-generated recommendation logic → persistent preference objects | Adaptive Recommender Agents |
| Embodied Agents | Motion planning → kinematic code → simulation pre-check → safe physical execution | RT-2, VIMA, HuggingGPT-Robot |
Open Challenges & Research Frontiers
Despite rapid progress, critical gaps remain:
🔹 Evaluation Beyond Final Success
Current metrics (e.g., test pass rate) ignore architectural debt, maintainability, and technical elegance. We need semantic-level code quality benchmarks.
🔹 Verification Under Incomplete Feedback
Security vulnerabilities, performance cliffs, and side-channel leaks evade standard unit tests. New non-functional verification primitives are urgent.
🔹 Regression-Free Evolution
Automated scaffold optimization risks “catastrophic forgetting.” Requires causal impact analysis before any change.
🔹 Semantic Conflict Resolution
Git merge handles syntax — not business logic conflicts. Need multi-agent semantic diffing and conflict-aware co-editing protocols.
🔹 Human-in-the-Loop Safety Governance
Production/physical access demands hard-gated approval workflows, immutable audit logs, and zero-trust runtime interception.
Conclusion: Code Is the Skeleton, Nerves, and Muscles of AGI
This survey delivers more than analysis — it offers an engineering blueprint for trustworthy, scalable, real-world AI.
Large language models are the brain. But code — executed, inspected, and shared — is the skeleton that holds structure, the nerves that carry feedback, and the muscles that act upon the world.
Without this code-first harness, agents remain brittle demos. With it, they evolve into industrial-grade collaborators — in software, science, interfaces, and embodied systems.
Source: “Code as the Universal Agent Harness” — Joint Survey by UIUC, Meta AI, and Stanford HAI (2026). Summary by AI修猫Prompt.