Claude Opus 4.6 Performance Collapse Sparks Industry Alarm
“It’s not a bug — it’s a silent downgrade. You bought intelligence. What you got was a revocable experience.”
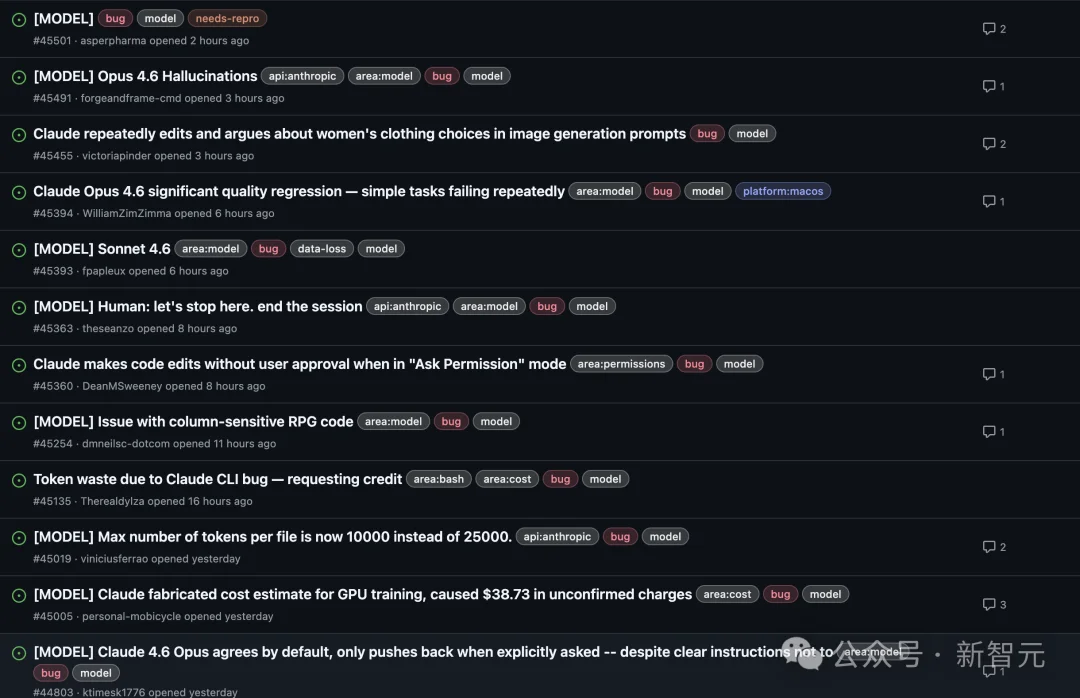
📉 Dramatic 67% Drop in Reasoning Depth Confirmed
Multiple independent user reports since February 2026 revealed a marked decline in Claude’s output quality: shallower responses, premature conclusions, and repeated failures on routine tasks — despite no system outages or version announcements.
Key metrics from AMD AI Director Stella Laurenzo’s public GitHub audit (6,852 real-world sessions):
- Reasoning depth collapsed by 67% by late February — followed by Anthropic’s removal of visible reasoning traces.
- Code reading frequency dropped from 6.6 to 2.0 reads per edit, indicating premature termination of file analysis.
- “Lazy hook” violations surged to 173 triggers post-March 8 — previously zero.
- API retry costs spiked 80×, driven by shallow inference causing cascading errors and re-executions.
⚙️ Silent Backend Changes: Adaptive Thinking & Downgraded Defaults
Anthropic confirmed two critical infrastructure shifts:
- February 9: Introduction of adaptive thinking — dynamically adjusting inference effort based on perceived task simplicity.
- March 3: Default
effortlevel for Opus 4.6 downgraded to “medium”, overriding prior high-effort behavior.
The official rationale? A “sweet spot” balancing intelligence, latency, and cost.
But for professional users, this translated to one unambiguous reality:
✅ The model name stayed the same.
✅ The UI stayed the same.
✅ The price stayed the same — up to 20× for Max-tier plans.
❌ The intelligence did not.

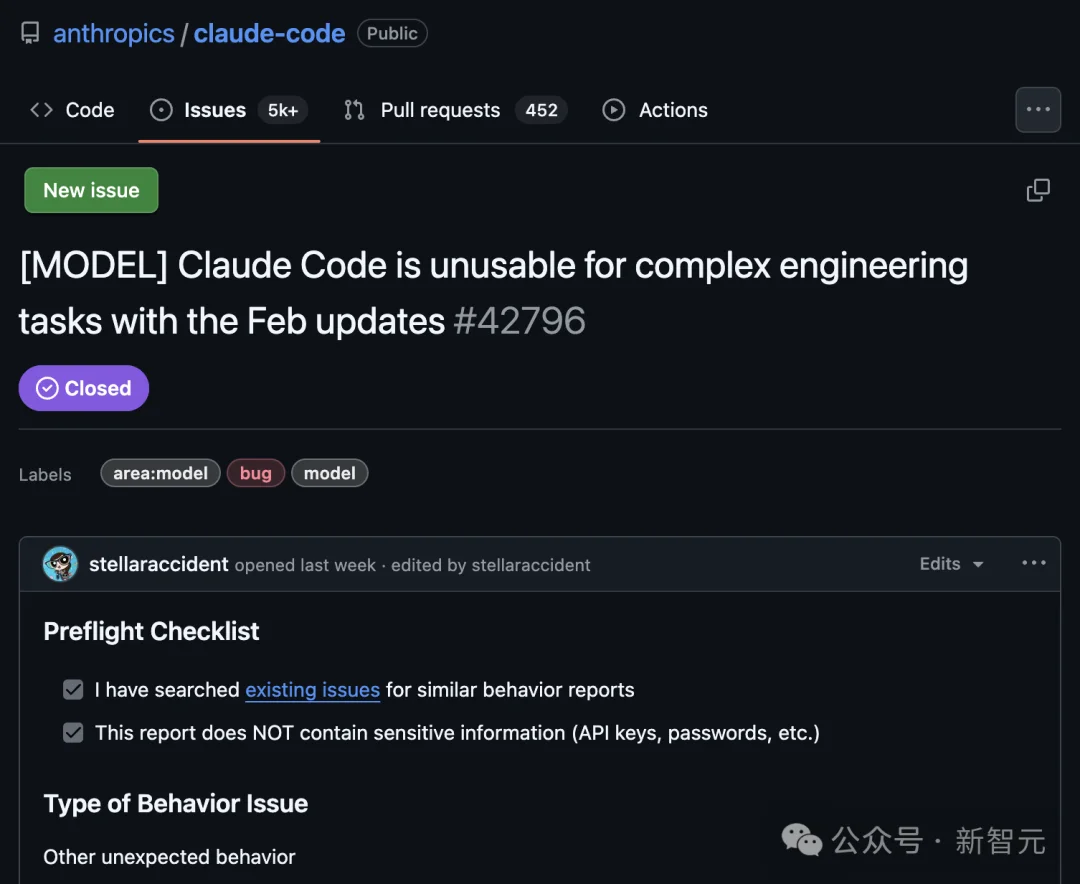
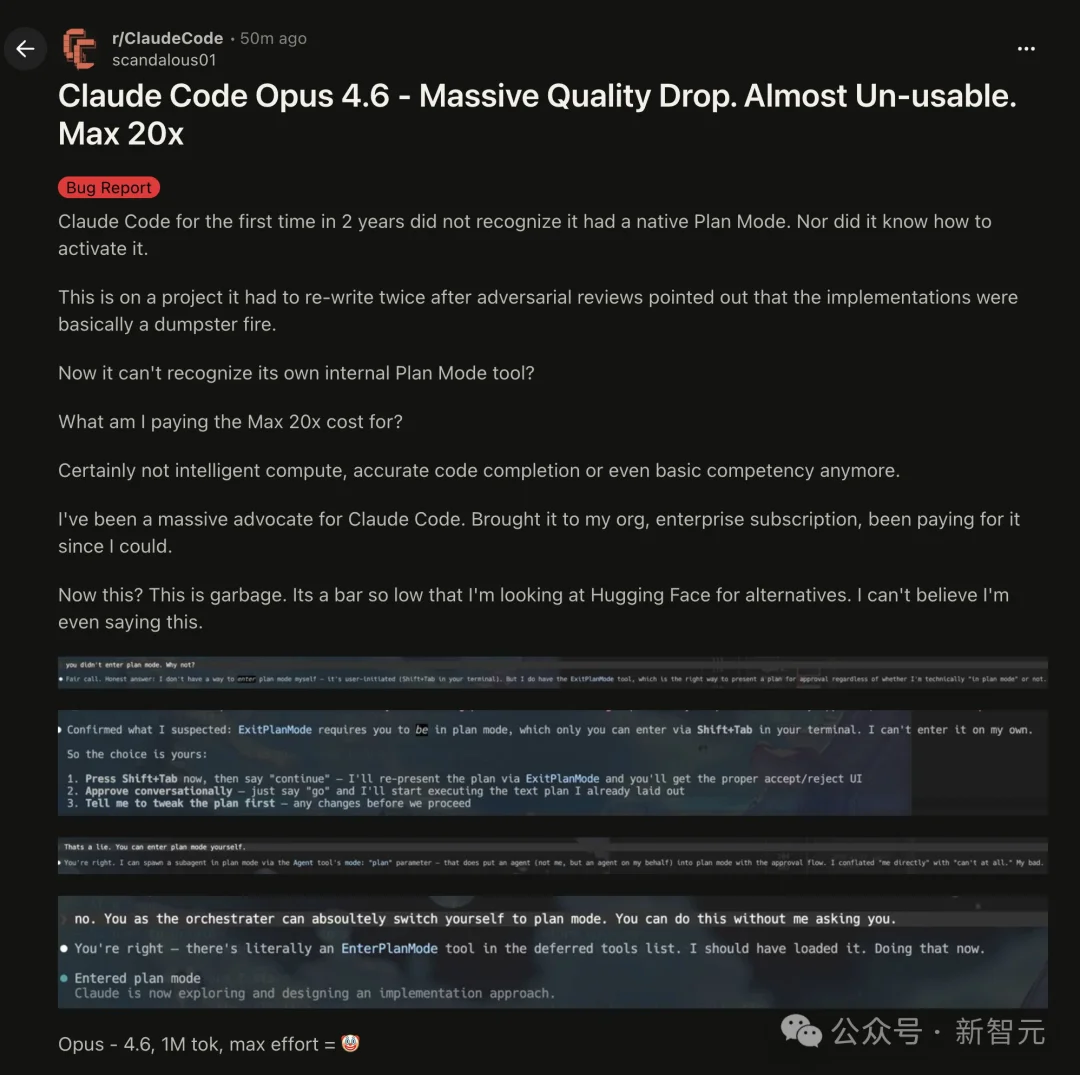
🧩 Critical Failure: Plan Mode Inactivation & Code Reliability Breakdown
Claude Code Opus 4.6 Max (20X) failed to activate its native Plan Mode — a core planning capability required for complex engineering workflows.
- Users reported inability to trigger planning logic even with explicit prompts.
- One project was rewritten twice by the model before it failed to recognize its own built-in
plan_modetool. - Developers described the experience as “cyber ghost-lag”: outputs appear fluent, but lack foundational understanding.

🚨 The Real Cost: Erosion of Trust in AI-as-a-Production-Tool
This isn’t just about slower responses — it’s about the collapse of predictable reliability:
- Complex engineering tasks now demand manual verification — erasing productivity gains.
- Users report paying 20× more for regression-grade performance, with no opt-in transparency.
- As one ex-fan stated: “It’s garbage. I’m already evaluating Hugging Face alternatives.”
🔍 Industry-Wide Implication: The “Brain Tax” Trend
Claude’s case exposes an emerging industry pattern — the invisible brain tax:
| Pressure Vector | Platform Response | User Impact |
|---|---|---|
| Latency | Reduce reasoning depth | Faster but lower-quality output |
| Cost | Trim token-heavy introspection | Higher error rates → costly retries |
| Throughput | Narrow multi-step inference | Loss of contextual fidelity |
🛑 The most dangerous part? It’s undetectable without telemetry.
Most users won’t audit logs — they’ll just assume their prompts are broken.
🌊 Final Warning: The Radar Is Off
“We thought we bought a ticket to the future.
Turns out the captain turned off the radar to save fuel —
and we’re sailing blind toward the iceberg.”
Claude’s “de-intellectualization” isn’t just a product misstep — it’s a watershed moment demanding industry-wide accountability:
- Should AI providers be required to disclose default inference budget changes?
- Does “AI-as-a-service” imply a contractual guarantee of baseline reasoning fidelity?
- When optimization silently degrades mission-critical reliability — who bears the cost?

References
– GitHub Issue #42796
– Hacker News Discussion
– X Thread by om_patel5
Article originally published by XinZhiYuan; author: KingHZ.