ByteDance Unveils Cola DLM: Open-Source Continuous Latent Diffusion Language Model
Big language models don’t have to predict the next token — they can model language directly in continuous semantic space.
In a landmark move challenging decades-old LLM paradigms, ByteDance’s Seed team has open-sourced Cola DLM (Continuous Latent Diffusion Language Model), a novel architecture that shifts generative modeling from discrete token space into a unified, continuous latent space — echoing and extending the vision behind He Kai-Ming’s recent ELF model.

Beyond Token Prediction: A Semantic-Centric Paradigm
Cola DLM is built on a foundational insight: tokens are not semantics — they’re historical artifacts of tokenization. As the team boldly states:
✦ “Tokens are surface carriers of human language — not semantics themselves.”
This philosophy drives a radical architectural split:
- Latent Prior (DiT + Flow Matching): Learns to generate meaningful semantic states from noise in continuous space.
- Decoder: Translates those latent representations into coherent text — only at the final step.
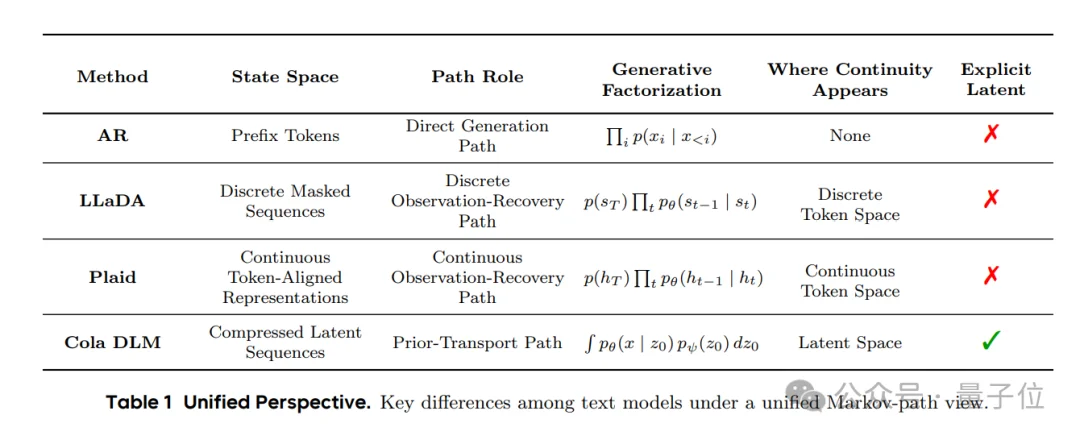
Unlike traditional diffusion language models (DLMs) that denoise masked or corrupted tokens, Cola DLM diffuses latent priors, not tokens. There is no incremental token generation — only semantic formation followed by deterministic realization.

Four Engineering Breakthroughs
🔑 Key 1: Latent ≠ Embedding — Enter Text VAE
Cola DLM avoids naïve word embedding diffusion. Instead, it employs a dedicated Text Variational Autoencoder:
- Encoder: Compresses raw text into a probabilistic, continuous latent variable — capturing a “semantic fingerprint.”
- Decoder: Reconstructs text from latent codes — enabling true semantic abstraction, not token memorization.
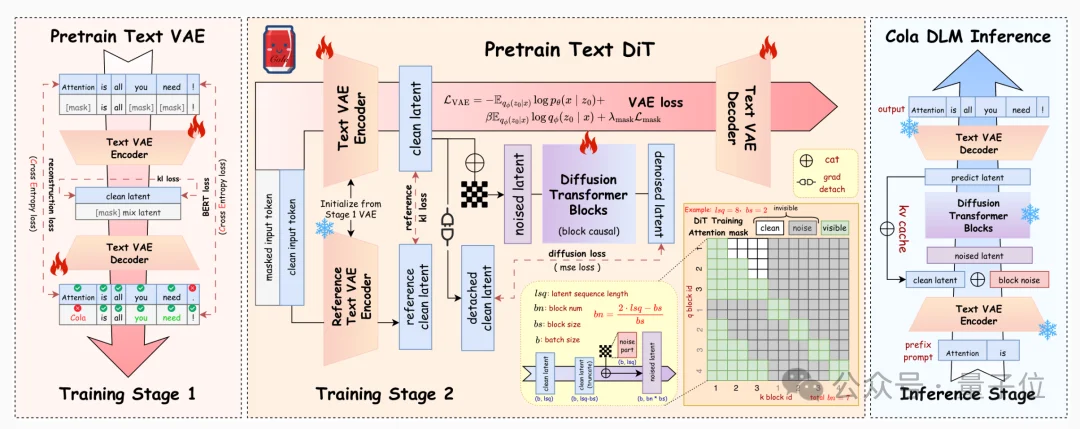
🔑 Key 2: Flow-Based Prior — Not Standard Diffusion
Instead of iterative denoising, Cola DLM uses block-causal DiT + Flow Matching, which:
– Starts from a simple distribution (e.g., Gaussian),
– Learns a smooth vector field over continuous time,
– “Transports” noise into the true latent data distribution — in one optimal path.
The block-causal design enables parallel local semantic organization while preserving global causal coherence.
🔑 Key 3: Strict Role Separation During Training
To prevent latent collapse into token-like representations, Cola DLM enforces strict task isolation:
- Encoder/Decoder: Trained only on reconstruction (BERT-style masked loss ensures semantic fidelity).
- Prior (DiT+FM): Trained only on latent distribution matching — with Encoder frozen during this phase.
This prevents the encoder from “cheating” to simplify prediction — enforcing a stable, abstract semantic space.
🔑 Key 4: Modular, Diagnosable Objectives
Cola DLM decomposes training into three orthogonal, measurable subtasks:
| Objective | Purpose | Diagnostic Metric |
|---|---|---|
| Reconstruction | Can decoder recover original text from latent? | BLEU, ROUGE, exact match |
| Compression | How much linguistic information is retained in latent? | KL divergence, mutual information |
| Prior Fit | Does prior learn true latent distribution? | Flow matching loss, sampling fidelity |
This modularity enables precise debugging — a stark contrast to monolithic autoregressive loss.

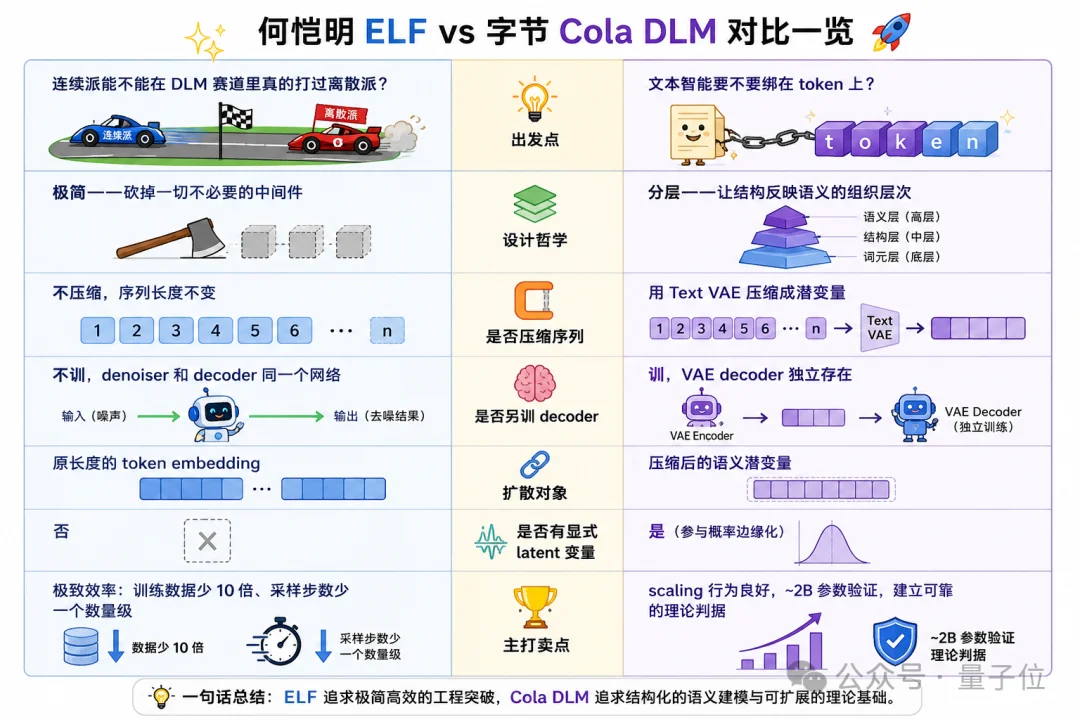
Cola DLM vs. ELF: Two Paths, One Vision
While both Cola DLM and He Kai-Ming’s ELF reject token-level diffusion, their implementations diverge meaningfully:
| Aspect | ELF | Cola DLM |
|---|---|---|
| Architecture | End-to-end diffusion in fixed-length embedding space | Two-stage: VAE + separate prior + decoder |
| Workflow Analogy | One person drafting iteratively until final output | Two departments: semantic strategy → textual execution |
| Core Motivation | Prove continuous-space viability (105M params) | Build scalable, modular, multi-modal-ready foundation (~2B params) |
The Bigger Picture: Bridging Modalities
Cola DLM’s ambition extends far beyond language generation. Its true strategic significance lies in solving a core bottleneck of multimodal AI:
🌐 Text is discrete; vision, audio, and video are inherently continuous.
By mapping text into a shared continuous latent space — compatible with image/video diffusion backbones like Stable Diffusion — Cola DLM serves as a universal interface for cross-modal alignment. It’s not just another LLM — it’s a bridge into the continuous multimodal world.
As the authors conclude modestly but powerfully:
“Cola DLM is an early step — but the path itself is worth walking.”
Research Team & Open Resources
Led by ByteDance’s Seed team and collaborators from HKU, Renmin University, Peking University, BUPT, and ANU, Cola DLM features exceptional academic-industry synergy:
- First Author: Hongcan Guo (BUPT undergrad, ByteDance Seed intern) — author of the official technical blog.
- Corresponding Author: Yan Zeng — architect of Seedance (ByteDance’s flagship video generation series).
- Cross-Disciplinary Contributors: Includes Shen Nie (first author of discrete DLM LLaDA), Hengshuang Zhao (HKU, ex-MIT/OU), Qiushan Guo (HKU MMLab, Seedream co-developer).
✅ Fully Open-Sourced:
– Hugging Face Hub
– GitHub Repository
– arXiv Paper
– Technical Blog (EN/zh)


Article originally published by QuantumBit; author: Yishui.