Alibaba Unveils Qwen3.5 During Spring Festival
A Strategic Leap in the AI Race — Just Before Lunar New Year
As the CCTV Spring Festival Gala prepared to air, the AI community was already electrified: Alibaba officially launched and open-sourced the Qwen3.5 series, delivering what many dubbed the “Spring Festival hard dish” — a bold, technically ambitious release timed for maximum impact.
In the past two weeks, Chinese internet users had flooded the Qwen app with prompts — all chasing a free milk tea reward. Backed by ¥3 billion in subsidies, the campaign drove explosive growth:
- 📱 Top ranking on the App Store
- 📊 Daily active users (DAU) surged to 73.52 million, matching ByteDance’s Doubao
- 🧾 120 million AI orders in just 6 days
This marked the first mass-market adoption of large language models (LLMs) among Chinese consumers — but as the industry knows well: subsidy-driven traffic fades fast. The real challenge? Turning fleeting attention into lasting engagement. The answer lies in model excellence — and Qwen3.5 delivers.

Two Flagship Models: Power + Efficiency Redefined
Qwen3.5 is deployed live on chat.qwen.ai and comprises two distinct variants:
| Model | Key Characteristics | Use Case Focus |
|---|---|---|
| Qwen3.5-Plus | Latest general-purpose LLM; 400B parameters | High-performance reasoning, coding, multimodal tasks |
| Qwen3.5-397B-A17B | Open-source flagship; MoE architecture (397B total / 17B activated) | Cost-efficient inference, developer deployment, research |
✅ Both support text, image, and video understanding — natively trained across multimodal data.

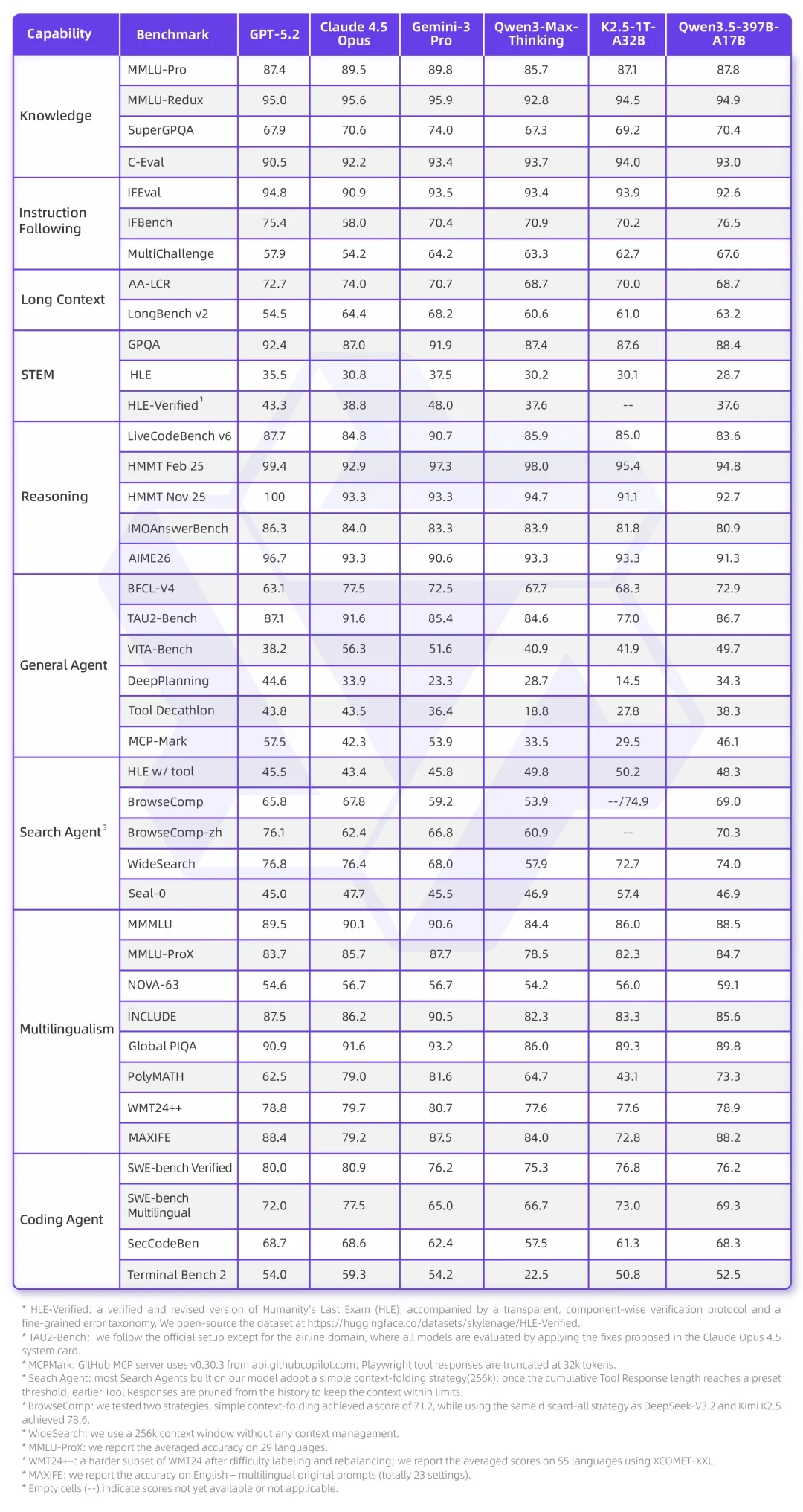
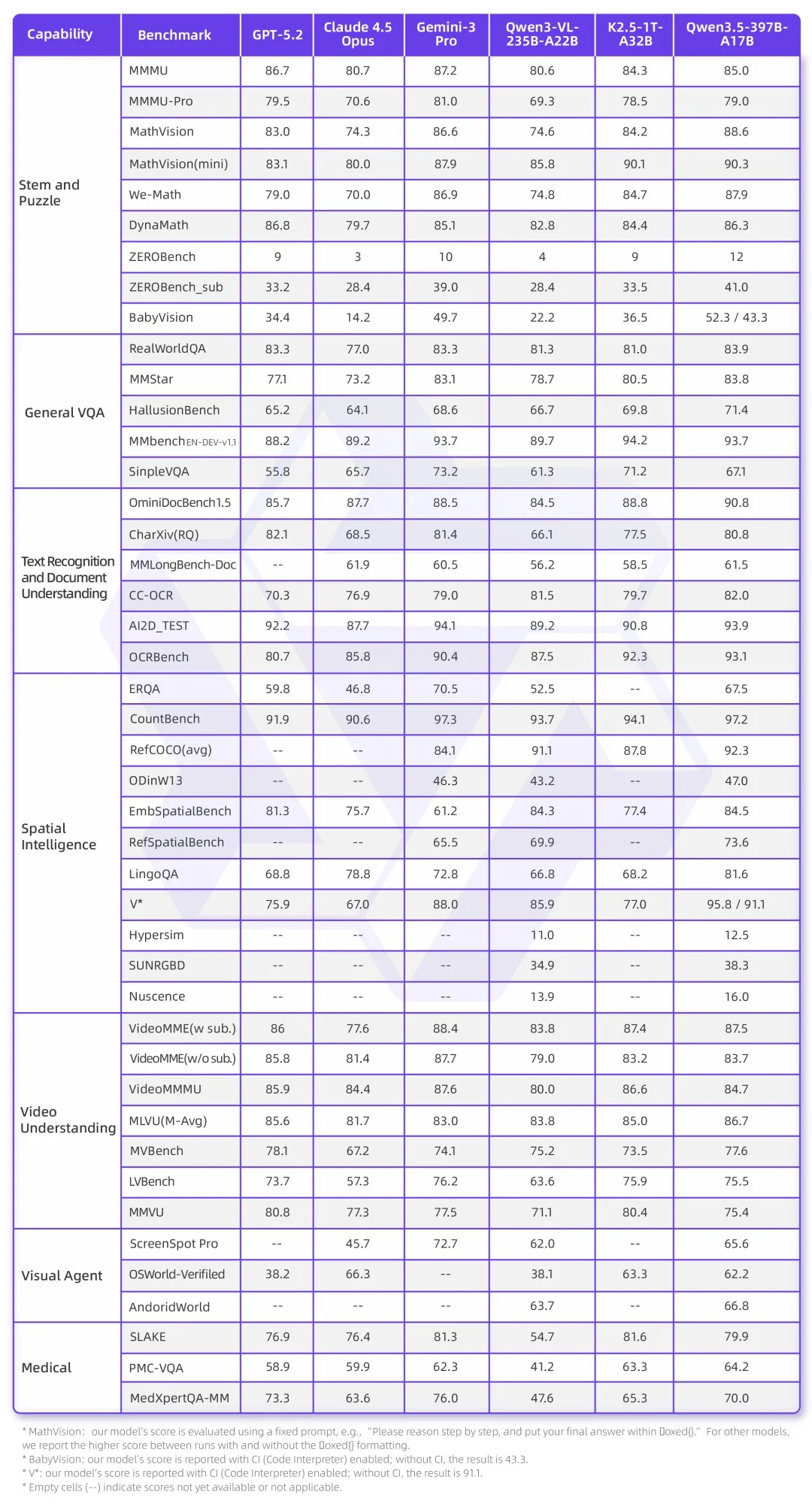
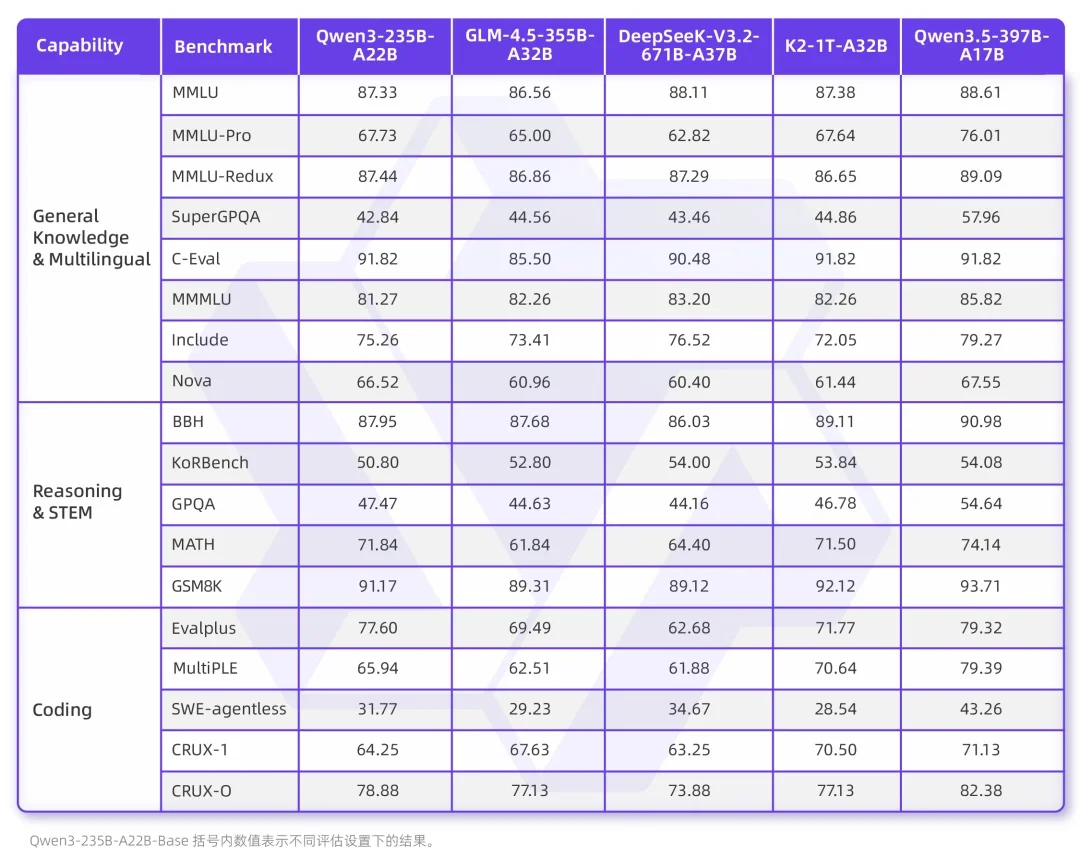
Benchmark Dominance & Technical Breakthroughs
Qwen3.5 dominates open benchmarks — rivaling top-tier closed models like Gemini-3-Pro in:
- Multimodal comprehension (image + video + text)
- Complex reasoning & chain-of-thought logic
- Code generation & debugging
- Agent-level autonomy (cross-app task orchestration)
Notably, Qwen3.5-Plus outperforms the previous trillion-parameter Qwen3-Max, proving intelligence isn’t just about scale — it’s about architecture.
Core Innovations Driving Performance
🔹 Hybrid Attention Mechanism
Dynamic allocation of compute resources — enabling efficient long-context processing (up to 1M tokens) and seamless handling of 2-hour videos.
🔹 Ultra-Sparse Mixture-of-Experts (MoE)
Only ~4.3% of total parameters (17B/397B) activated per inference, slashing latency and cost without sacrificing capability.
🔹 Native Multi-Token Prediction
Replaces autoregressive single-token generation with parallel multi-step prediction — doubling inference speed.
🔹 Heterogeneous Multimodal Training
Decoupled visual & language pipelines + cross-module computation overlap → ~100% throughput gain over pure-text baselines.
🔹 FP8 Pipeline with Runtime BF16 Guardrails
Low-precision activation, routing, and GEMM operations — combined with dynamic precision fallback on sensitive layers → 50% less activation memory, >10% faster training, stable scaling to trillions of tokens.
Real-World Performance: From Invoices to Interactive Games
We stress-tested Qwen3.5 across practical scenarios:
✅ Document Intelligence
Accurately extracted structured data from complex invoices — no hallucination, no misalignment.

✅ Visual Comparison (“Spot the Difference”)
Identified all discrepancies between two near-identical images — even subtle UI variations — though without inline annotation.

✅ Multimodal Sentiment & Subtext Understanding
Interpreted meme imagery and its underlying irony and cultural nuance — a true test of contextual grounding.

⚠️ Writing Quality: Room for Growth
While logically sound, generated prose retains detectable “AI flavor” — stilted transitions, limited stylistic flair, and minimal emotional texture.

💥 Coding Excellence: A Standout Strength
- Generated a fully functional Chinese New Year fireworks simulator — with physics, visuals, and synchronized audio.
- Built an interactive Nian Beast Tower Defense Game: red-themed slowdown mechanics, NPC dialogue, cartoon aesthetics — all in one prompt.
- Created a responsive, animated Lunar New Year greeting webpage — deployed instantly.
🌟 Qwen3.5’s coding fluency — including aesthetic awareness, error resilience, and self-repair — places it firmly in the top tier of open models, matching or exceeding leading closed alternatives.
Pricing: Disruptive Value at Scale
| Model | Price (per 1M tokens) | Compared to Gemini-3-Pro |
|---|---|---|
| Qwen3.5-Plus API | ¥0.8 ($0.11) | 1/18th the cost |
This pricing strategy lowers the barrier for startups, researchers, and enterprise integrators — accelerating real-world adoption beyond benchmark scores.
The Bigger Picture: Innovation Over Parameter Bloat
Last year, DeepSeek V3 redefined global AI narratives with “smaller but smarter.” This year, Qwen3.5 doubles down on that philosophy — proving that intelligent architecture, multimodal-native design, and system-level optimization can outperform brute-force scaling.
As subsidies expire and novelty wears off, only technical depth and economic efficiency will sustain leadership. With Qwen3.5, Alibaba hasn’t just released a model — it’s issued a manifesto for the next phase of open AI.
🎇 On Chinese New Year’s Eve, while performers dazzled on stage, the real blockbuster unfolded in data centers — a quiet, confident declaration of what comes next.
Article originally published by APPSO.