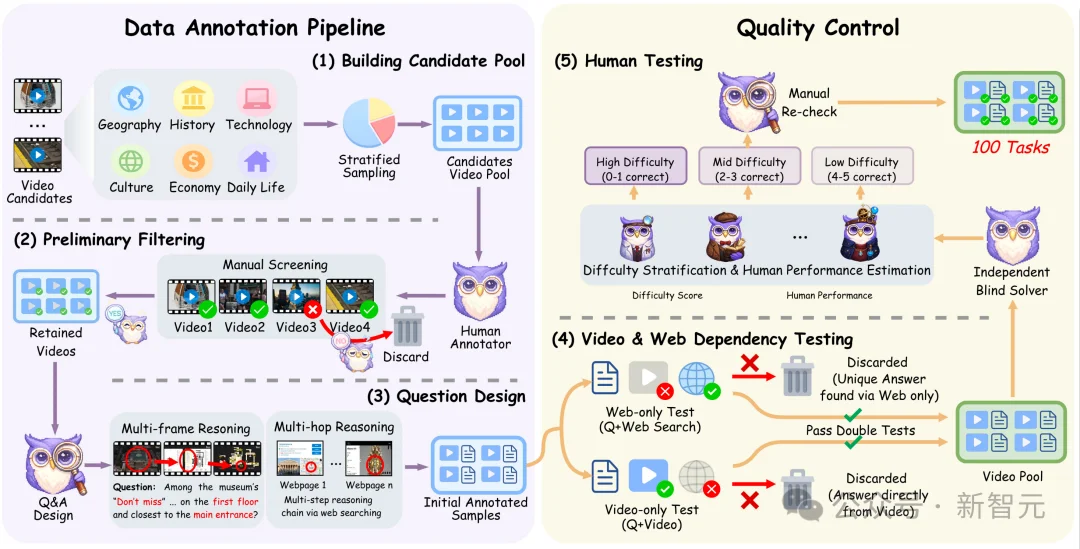
VideoDR: First Benchmark for Video Deep Research
Existing multimodal models are often trapped in the “video island”—they can only answer questions confined to the video content itself. In contrast, human problem-solving in the real world follows a three-step process: watch video → search online → reason holistically.
To bridge this gap, researchers from QuantaAlpha, Lanzhou University, HKUST(GZ), Peking University, and other institutions have introduced VideoDR, the first open-world video deep research evaluation benchmark.
Why VideoDR?
Traditional VideoQA vs. Real-World Intelligence
- Standard VideoQA: Answers reside entirely within the video.
- Video Deep Research: Requires cross-modal reasoning—extracting visual clues from video and grounding them with external evidence via live web search.
💡 Example Task:
“Given a museum exhibit shown in a video, what is the registration number of the closest recommended exhibit listed on the museum’s official website?”This demands:
– Precise object detection & spatial localization from video frames,
– Navigating the museum’s website to retrieve maps, recommendation lists, and metadata,
– Multi-hop factual synthesis across modalities.

Core Task Design Principles
VideoDR introduces a rigorous, human-annotated paradigm centered on three interdependent capabilities:
-
Multi-Frame Visual Clue Extraction
Accurately identify and track temporally consistent semantic cues across multiple video frames.
-
Interactive Web Search
Perform multi-turn, goal-directed browsing in realistic browser environments—not just keyword queries.
-
Multi-Hop Fact Verification
Synthesize video-derived context + retrieved web evidence into verifiable, citation-backed answers.

Rigorous Evaluation Methodology
- ✅ Human-Curated & Validated: No synthetic data—every question, search path, and answer underwent expert annotation and QA.
- ✅ Dual-Dependency Enforcement: All samples were filtered to exclude those solvable only by video or text alone—ensuring true cross-modal integration is required.
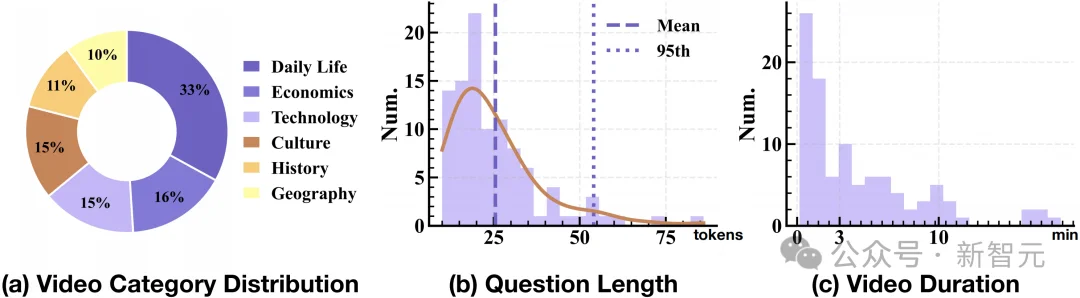
- ✅ Diverse Domain Coverage: Tasks span 6 real-world domains: Daily Life, Economics, Technology, Culture, History, and Geography.
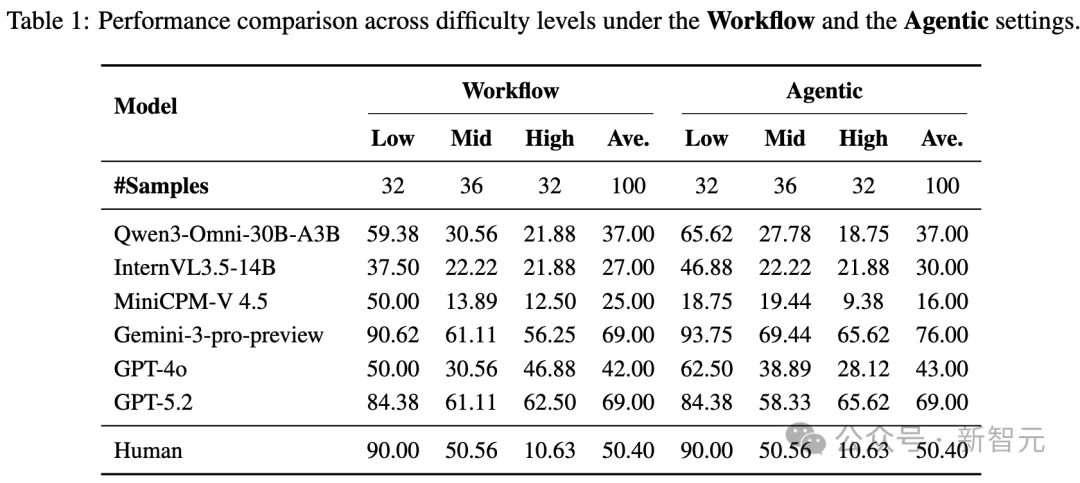
Workflow vs. Agentic Paradigms
Researchers systematically compared two dominant agent architectures:
| Paradigm | Description | Key Strength | Key Limitation |
|---|---|---|---|
| Workflow | Video → structured textual summary → search → reasoning | Explicit intermediate memory prevents goal drift; robust on long videos | Less flexible; pipeline bottlenecks may limit adaptability |
| Agentic | End-to-end video+browser interaction; autonomous decide-when-to-search | High flexibility & autonomy | Prone to goal drift under long-horizon tasks; initial perception errors cascade irreversibly |
Evaluated Models
- Closed-Source: GPT-5.2, GPT-4o, Gemini-3-pro-preview
- Open-Source: Qwen3-Omni-30B-a3b, InternVL3.5-14B, MiniCPM-V 4.5
Key Findings
🥇 Top Performers
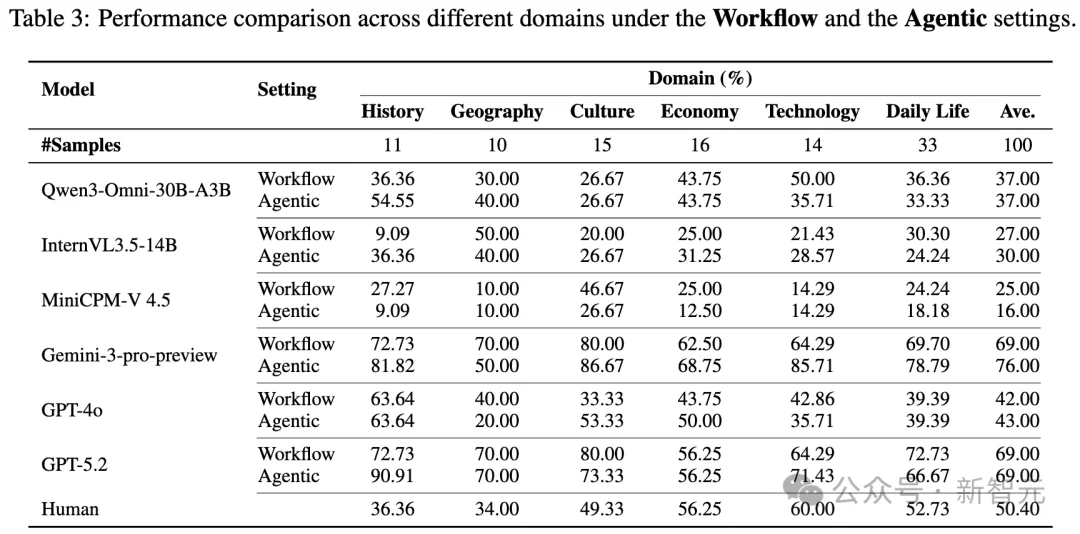
- Gemini-3-pro-preview and GPT-5.2 lead with 69–76% accuracy, significantly outperforming peers.
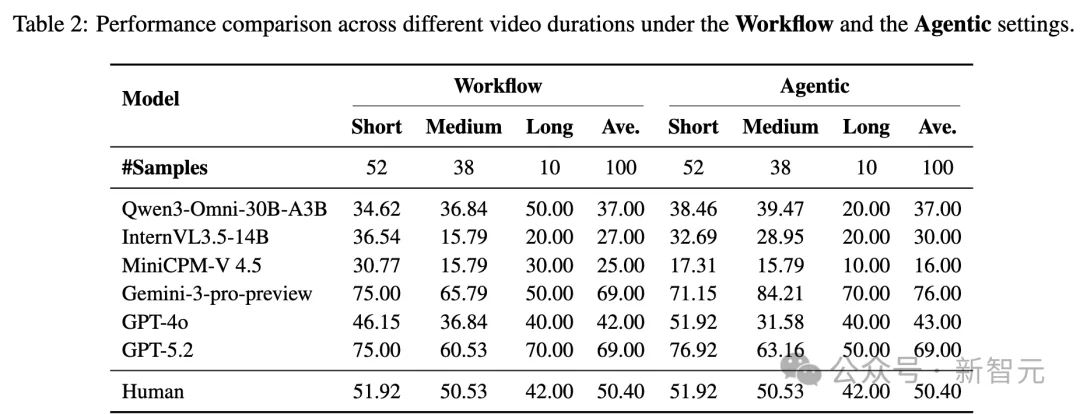
⚖️ Agentic ≠ Always Better
- While Agentic models excel in short, focused tasks, they suffer severe degradation on long videos due to long-horizon inconsistency.
- Workflow models retain fidelity to original visual cues via explicit textual intermediaries—acting as “external memory.”
📏 Long Videos: The Ultimate Stress Test
- Long-duration inputs expose critical weaknesses in temporal coherence:
- Gemini-3 (Agentic) leverages extended context for marginal gains.
- Several open-source models drop sharply in accuracy—highlighting architectural fragility.
Conclusion & Implications
VideoDR redefines video understanding—from closed-domain QA to open-world, evidence-grounded research.
🔍 Critical Insight: “End-to-end” does not guarantee superior performance. In complex, multi-step reasoning, structured intermediation (Workflow) often outperforms raw autonomy—especially when long-term visual consistency is essential.
🚀 The Path Forward: Next-generation Video Agents must innovate in long-horizon visual memory retention, enabling faithful recall and reuse of frame-level details across minutes of video and dozens of search steps.
References
📄 Paper: arXiv:2601.06943
💻 Code: GitHub — QuantaAlpha/VideoDR-Benchmark