7B Model Beats o3 and GPT-5 in Medical AI Vision Reasoning
Medical AI doesn’t just write explanations — it must truly see the evidence.
A Paradigm Shift: From Passive Viewing to Active Visual Reasoning
Traditional medical multimodal models encode images or videos into static visual features, then generate answers and explanations via large language models. But clinical decisions hinge on microscopic clues: a subtle lesion boundary, a fleeting surgical motion, or a transient endoscopic finding — often lasting only seconds.
When models passively ingest visual context, they frequently misfocus, miss pathologies, or misinterpret normal anatomy as abnormal. This limitation isn’t about language capability — it’s a fundamental gap in visual interaction intelligence.
To bridge this, the LeapQuest team (Shanghai Institute of Innovation) — in collaboration with Zhejiang University, Shanghai Jiao Tong University, and Fudan University — introduced two ICML 2026 papers pioneering the Think with Images and Think with Videos paradigms for medical AI:
- ✅ Models no longer merely generate explanations after viewing — they actively invoke visual tools mid-reasoning to re-examine critical regions or moments.
- ✅ Visual evidence transitions from input to an integral component of the reasoning chain.
- ✅ Explanation becomes evidence-verified inference, not post-hoc justification.
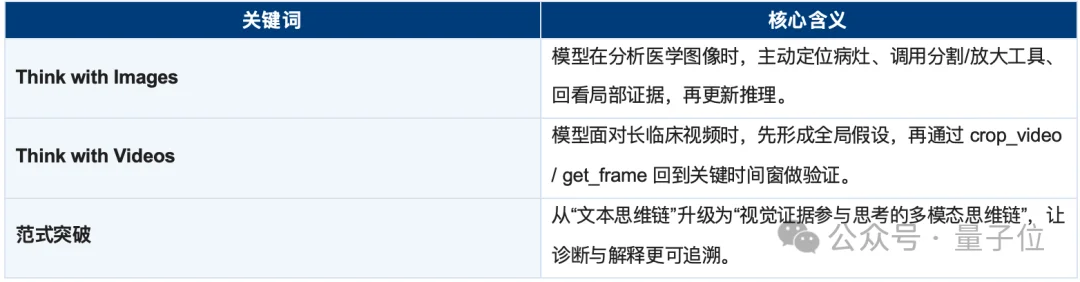
Ophiuchus: Think with Images for Precision Medical Imaging
Ophiuchus transforms LLMs into collaborative visual agents, dynamically selecting and applying domain-specific tools based on real-time reasoning needs:
- 🔍 SAM2: Pixel-precise lesion segmentation
- 🎯 BiomedParse: Text-guided anatomical structure localization
- ➕ Zoom-in: Adaptive magnification of suspicious regions
Each tool’s output is ingested as an observation token — directly feeding the next step in the reasoning chain.
Unlike external plugin architectures, Ophiuchus embeds tool usage into the CoT itself: the model learns when to call a tool, which tool to select, how to interpret outputs, and how to self-correct when evidence contradicts hypotheses.

Benchmark Leadership: Small Model, Superior Vision
On 8 VQA benchmarks, Ophiuchus-7B achieves 68.0 average score, outperforming:
- OpenAI-o3: 62.2
- Gemini 2.5 Pro: 61.8
- GPT-5: 59.9
It also attains 97.9% tool-call accuracy, proving that finer-grained visual interrogation — not just scale — drives clinical reliability.
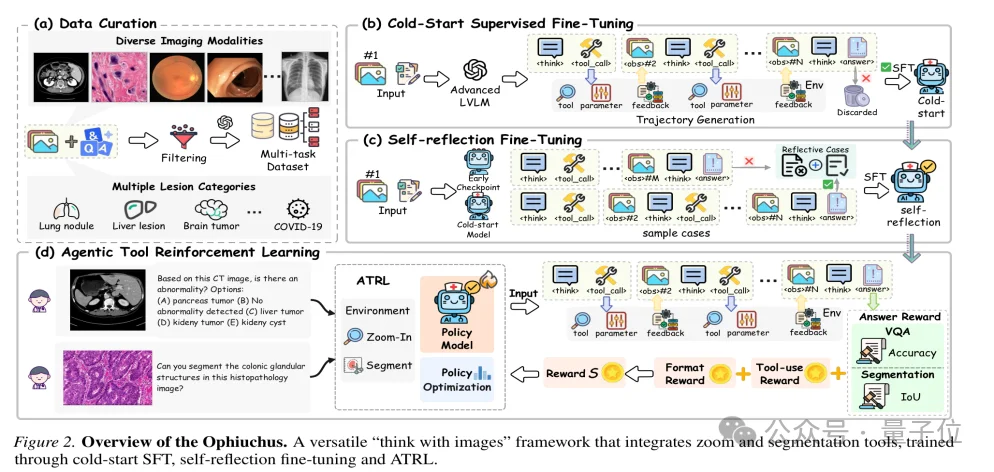
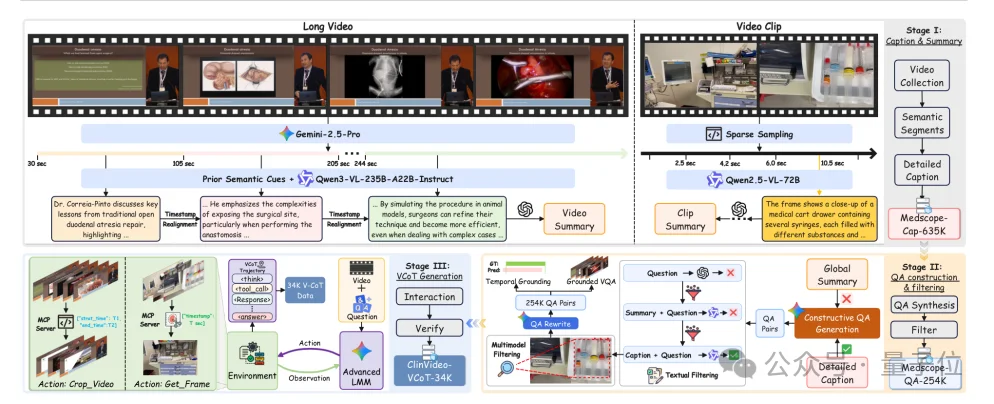
MedScope: Think with Videos for Clinical Temporal Reasoning
Where Ophiuchus solves fine spatial reasoning, MedScope tackles sparse, time-critical evidence in long clinical videos — such as laparoscopic procedures or endoscopic sequences.
Its “think with videos” approach mirrors expert clinician behavior:
- 🌐 First, build global contextual understanding
- ⏱️ Then, identify suspicious temporal windows
- ✂️ Use
crop_videoto extract key segments - 🖼️ Apply
get_frameto isolate decisive frames - 🔗 Integrate localized observations into final diagnosis
This yields inherently auditable reasoning: every answer is traceable to which video segment was reviewed, which frame was selected, and how evidence supports the conclusion.
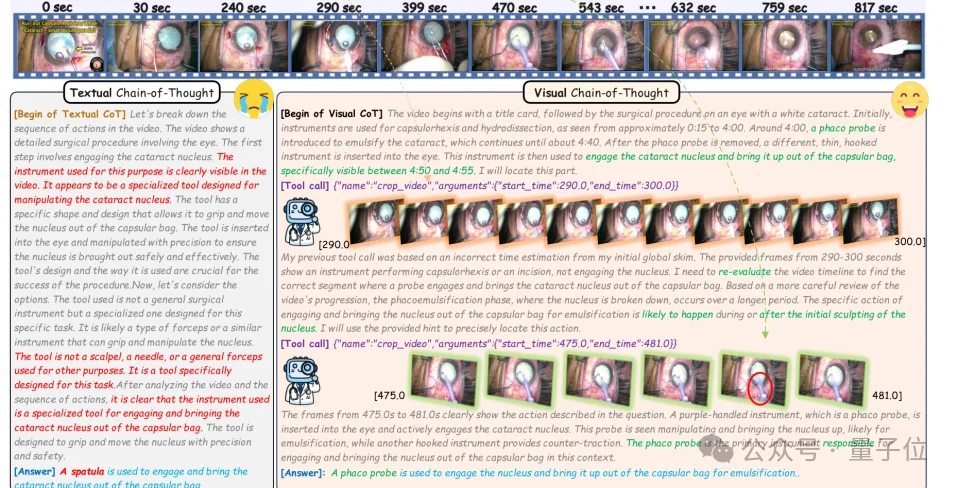
ClinVideoSuite & GA-GRPO: Training Evidence-Aware Agents
MedScope introduces:
- 📚 ClinVideoSuite: 635K timestamped captions, 254K evidence-linked QA pairs, and 34K visual-CoT trajectories
- 🧠 GA-GRPO: A grounding-aware reinforcement learning algorithm using evidence-modulated advantage to reward retrieval of clinically supportive visual snippets
Results show dramatic degradation without evidence rewards — e.g., R@0.5 drops from 40.1 → 33.2, confirming that answer-level supervision alone fails to teach reliable evidence selection.
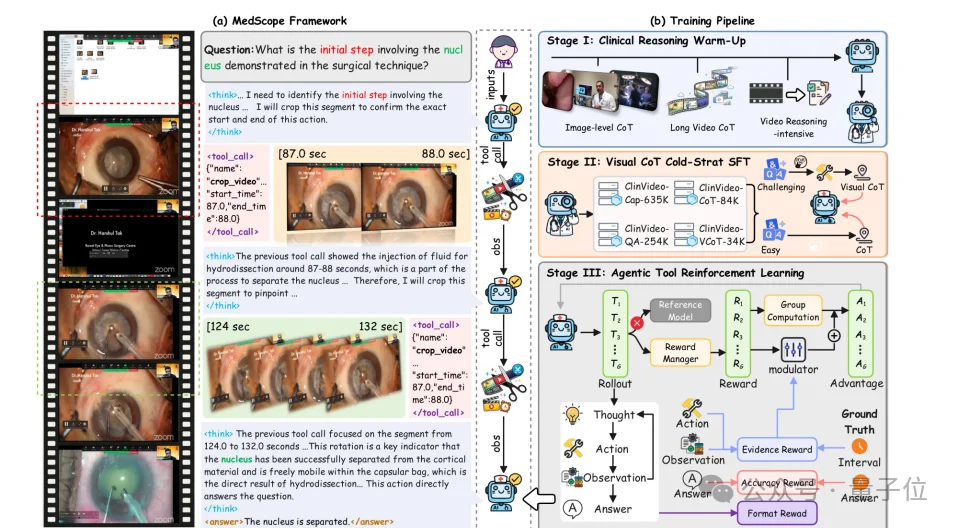
The Bigger Picture: Vision as Cognitive Process
Together, Ophiuchus and MedScope define a new foundation for clinical multimodal intelligence:
➡️ Reasoning is no longer a linear language sequence — it’s a closed-loop interaction among language tokens, visual tools, image regions, video segments, and evidence feedback.

This shift enables three critical capabilities for trustworthy clinical AI:
- ✅ Reduced hallucination (evidence-grounded outputs)
- ✅ Stronger explainability (auditable visual provenance)
- ✅ Robust process handling (stepwise verification for complex workflows)
Why This Is a Turning Point for Medical AI Agents
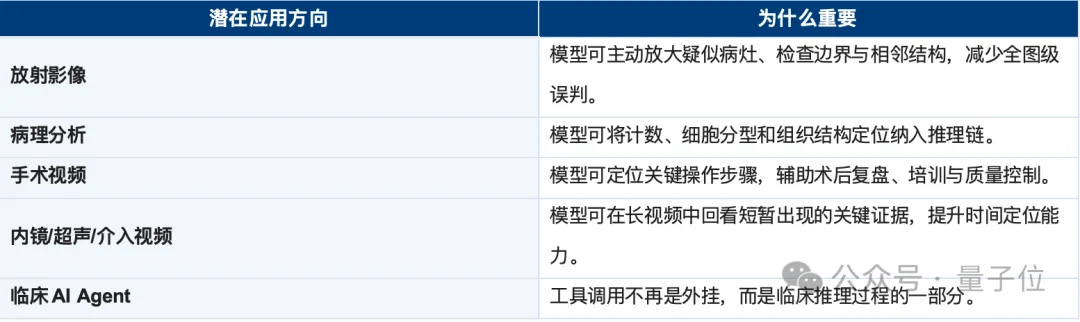
In medicine, every conclusion demands an evidence chain. Radiologists zoom margins. Pathologists scan cellular morphology. Surgeons replay maneuvers. Endoscopists track lesion evolution across time.
“Think with Images/Videos” aligns AI cognition with this inherently interactive, evidence-driven, and verifiable clinical practice — establishing an internal hypothesize → verify → refine → answer loop.
It redefines reasoning itself: not just language generation, but dynamic, goal-directed visual exploration.
When models can actively revisit imaging, magnify lesions, clip surgical clips, and validate findings — they move beyond answering questions toward performing clinical visual reasoning.
About LeapQuest
LeapQuest [Rising Horizon] is an interdisciplinary research team at the Shanghai Institute of Innovation, advancing next-generation medical AI agents, visual reasoning, and multimodal foundation models — focused on Visual Reasoning, Agentic RL, and Clinical Tool Integration.
🔗 GitHub Repositories:
– MedScope | Think with Videos: https://github.com/SII-WenjieLisjtu/MedScope
– Ophiuchus | Think with Images: https://github.com/SII-zyj/Ophiuchus
Article sourced from QuantumBit, authored by LeapQuest Team.