Ant Group LingBot-VA Unveils First Autoregressive Causal World Model

Breakthrough in Embodied AI: Bridging Physics Understanding and Real-Time Action
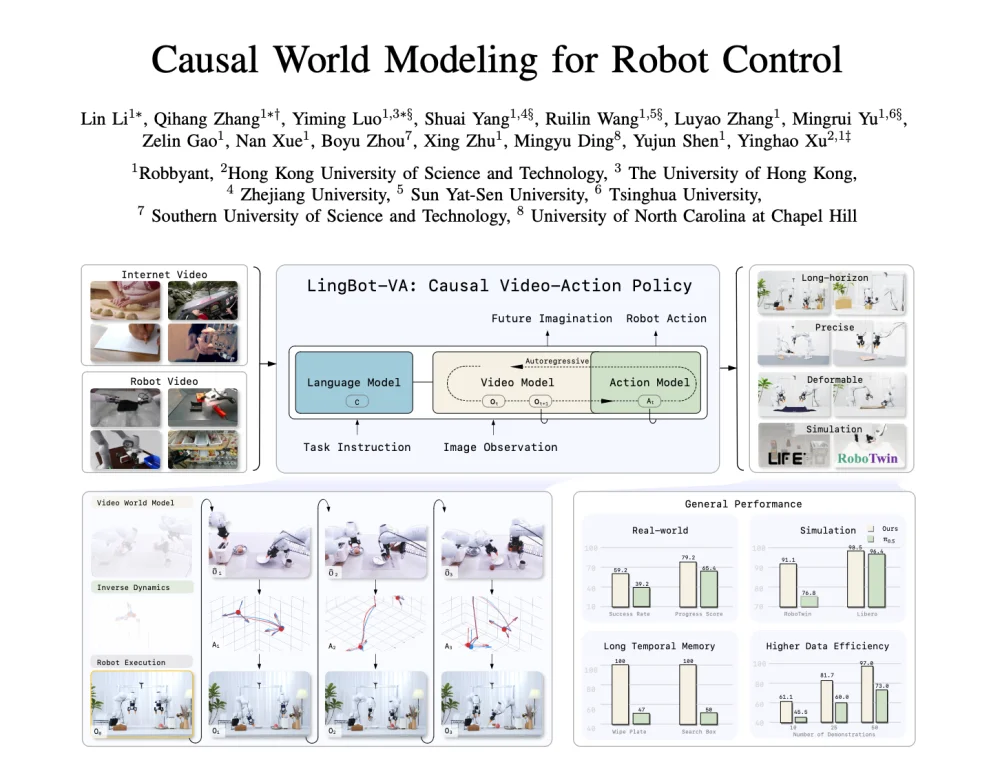
Granting robots physical intuition and causal prediction capability is foundational to general-purpose manipulation. To address this, researchers from Ant Group LingBo and HKUST introduced LingBot-VA, the world’s first autoregressive causal world model that unifies video frame forecasting and action reasoning — enabling robots to learn “think-while-acting” through an autoregressive diffusion framework.
Why This Matters: The Limits of Current VLA Models
Contemporary vision-language-action (VLA) models often map observations directly to actions or rely on short-horizon predictions. These approaches suffer from critical limitations:
- ❌ No explicit physical modeling: Prone to trajectory memorization instead of causal reasoning.
- ❌ Markovian assumptions: Discard history, impairing ambiguity resolution in partially observable or long-horizon tasks.
- ❌ Non-causal attention: Bidirectional video generation models break temporal causality and incur high inference latency — incompatible with real-time robot control.
Example: A robot must infer that “pushing a cup causes spilling” — not just recognize objects. Without grounding in physics-aware dynamics, robust planning fails in dynamic, unstructured environments.
LingBot-VA Architecture: A Unified Autoregressive Sequence
LingBot-VA treats video frames and action tokens as interleaved elements in a single causal sequence — jointly modeled via a novel Mixture-of-Transformers (MoT) architecture.
Core Innovations
| Feature | Technical Insight | Impact |
|---|---|---|
| Interleaved Autoregressive Generation | Video and action streams are decoupled but causally interleaved; high-capacity video experts predict future visual states, while lightweight action experts decode corresponding actions under strict causal masking. | Enables rich scene transition modeling + ultra-low per-step action decoding cost. |
| Persistent History Integration | Unlike fixed-window methods, LingBot-VA conditions every prediction on the full observation–action history. Real observations are streamed into KV cache during inference — anchoring policy in actual interaction history. | Grants exceptional temporal memory for multi-step reasoning and long-horizon coherence. |
| Noise-Latent Acceleration | Recognizing that robots need semantic structure, not pixel-perfect frames, LingBot-VA trains action experts to decode from partially denoised video latents. Inference can truncate denoising early. | Boosts real-time performance: ~2 Hz closed-loop control on a single RTX 5880 Ada GPU (≈0.5 sec/step). |
Implementation Pipeline
- Unified Dual-Stream MoT Design
- Initialized from pre-trained video generative models.
-
Video stream (high-capacity) + action stream (lightweight).
-
Causal State Encoding & Alignment
- Raw vision → compressed latent tokens via causal video VAE.
-
Actions → same-dimension embeddings via MLP → cross-modal alignment.
-
Two-Stage Prediction Mechanism
- Stage 1 (Visual Dynamics): Predict future visual states given history.
-
Stage 2 (Inverse Dynamics): Decode precise actions from desired visual transitions.
-
Efficient Training Strategy
- Joint optimization via Teacher Forcing + Flow Matching in a single forward pass.
Experimental Validation: SOTA Performance with Minimal Data
Evaluated across real-world platforms and major benchmarks — all with astonishingly low data requirements.
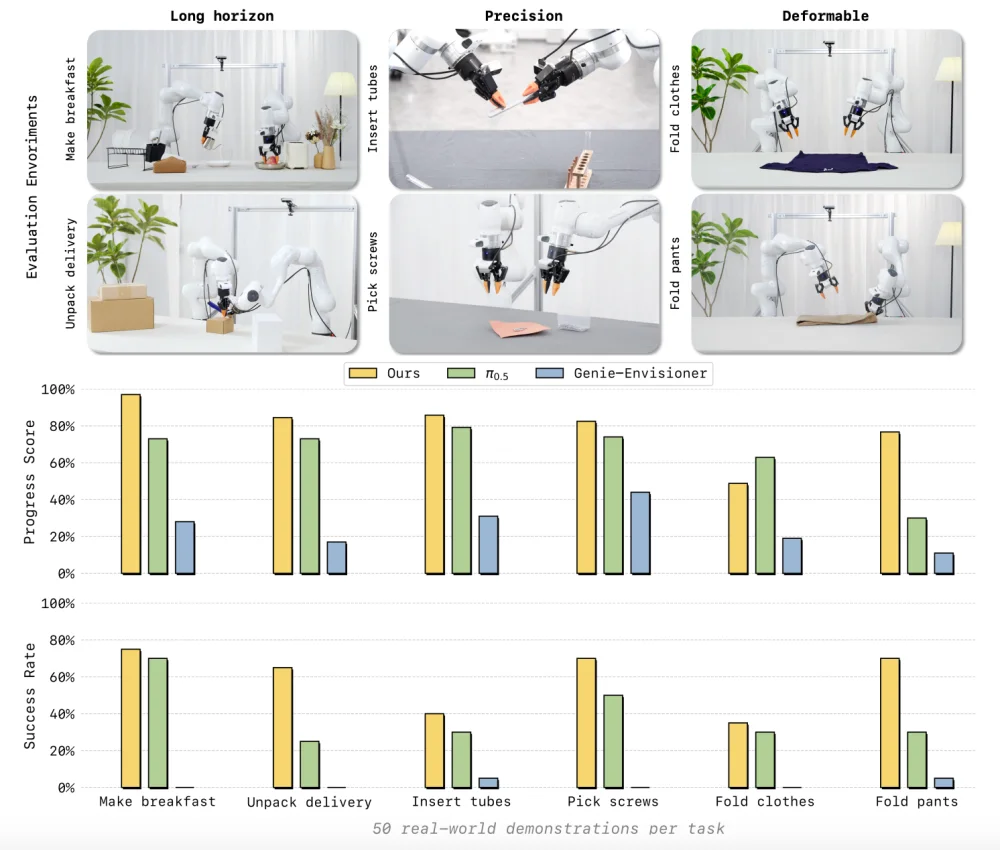
🌐 Real-World Deployment (50 demos/task)
Three challenging task categories:
– Long-horizon tasks: Breakfast preparation, package unpacking.
– High-precision tasks: Tube insertion, screw picking.
– Deformable object manipulation: Folding shirts & pants.
✅ Results: LingBot-VA achieves state-of-the-art success rates & progress scores, significantly outperforming strong baselines (π₀.₅, Genie-Envisioner). Its long-horizon strength confirms superior temporal memory; deformable-object robustness validates video generation as implicit physical guidance.
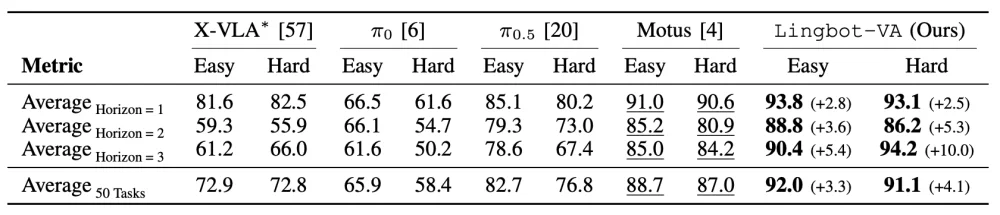
📊 Benchmark Results
| Benchmark | Setting | Avg. Success Rate | Notes |
|---|---|---|---|
| RoboTwin 2.0 (50 dual-arm tasks) | Easy | 92.0% | Highest among all published methods |
| Hard | 91.1% | Performance gap widens with complexity | |
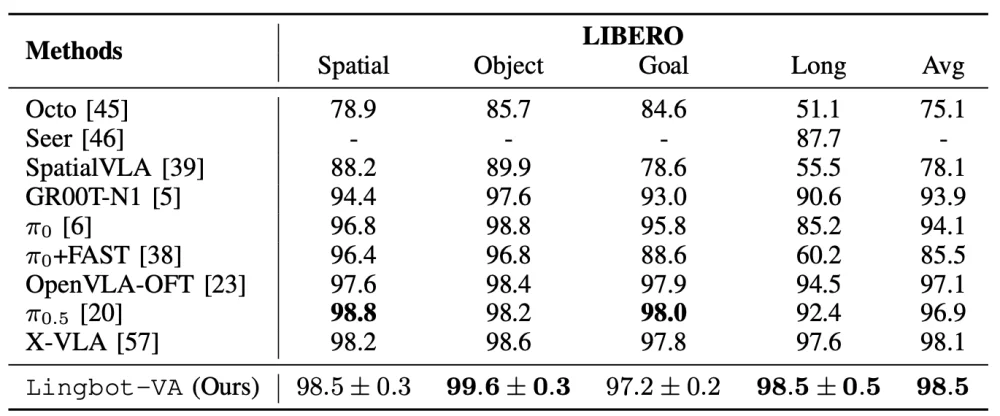
| LIBERO (4 suites: Spatial/Object/Goal/Long) | — | 98.5% | Near-perfect generalization across diverse goals |
🔍 Ablation Study Confirms Design Necessity
- Removing video prediction module → success plummets from 92.93% → 48.31%.
- Replacing causal masking with bidirectional attention → drops to 81.46%.
⚡ Efficiency Highlights
- Sample efficiency: Outperforms baselines even with only 10 demonstrations.
- Inference speed: 2 Hz real-world control frequency, enabled by noise-latent acceleration.
Conclusion & Future Directions
LingBot-VA redefines the paradigm for general robot control by embedding causal physical priors directly into the world model — not as post-hoc constraints, but as first-class generative dynamics.
It marks a decisive step toward truly embodied reasoning: robots that anticipate consequences, plan over extended horizons, and adapt seamlessly to physical complexity — all trained with minimal human demonstration.
Next Steps
- Developing more efficient video compression schemes to reduce compute overhead.
- Integrating multimodal sensory inputs: tactile, force, and audio signals for contact-rich manipulation.
LingBot-VA doesn’t just advance robotics — it accelerates the path to general-purpose, physically grounded AI agents.
🔗 Resources
- Paper: arXiv:2601.21998
- Project Page: https://technology.robbyant.com/lingbot-va