Agent Architecture: Storage-Compute Separation Design
A soulful, memory-equipped Agent’s task lifecycle includes the following steps:
- User inputs a query (text + files)
- Agent reads prompt files (
soul.md,identify.md,user.md, etc.) - Agent loads available tools and skills (
tools,skills, etc.) - Agent retrieves memory (
memory.md,memory_searchqueries) - Agent constructs context (
prompt+tools+memory+query) - Agent enters loop: LLM call → tool invocation → observation → re-reasoning
- Agent delivers artifacts (results, files, reports)
What to Store vs. What to Compute
| Category | Description |
|---|---|
| Storage | Prompt files, tools & skills definitions, conversation history, delivered artifacts |
| Computation | Context assembly, LLM inference, tool execution logic |
A concise functional representation:
fn(query, agent\ runtime) = artifacts
Three Agent Execution Models
- Bare-metal Local Execution
- Used by frameworks like OpenClaw
- All assets (prompts, skills, sessions) reside on local disk; workspace is fixed and shared
- ✅ Pros: Simple, no mount overhead
-
❌ Cons: High security risk — e.g.,
exec(rm -rf /)could compromise host -
Local Sandbox Execution
- Adopted by Codex-style agents
- Solves two key issues: privilege isolation and dependency consistency
- Tools requiring sensitive operations or external dependencies run inside sandbox; workspace mounts sync I/O bidirectionally
-
🔄 Separation limited to tool calls only — storage remains host-local
-
Cloud Multi-Instance Execution
- Typical for managed assistants (Manus, Kimi Claw, Max Claw)
- Designed for multi-tenancy, long-running memory, and concurrent task handling
- Traditional k8s + PVC approach leads to high cost: persistent pods, idle resource usage, poor scalability
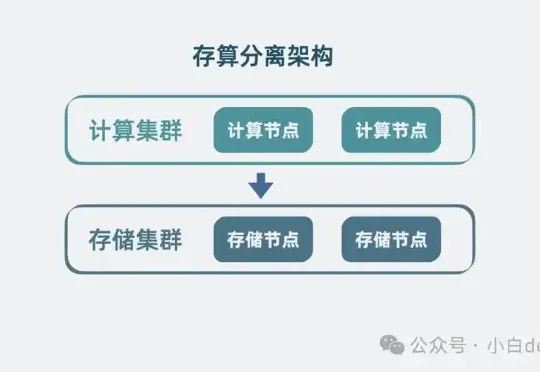
Storage-Compute Separation for Cloud-Native Agents
To achieve true scalability, modern cloud agents adopt serverless-inspired architecture, decoupling stateful storage from ephemeral compute:
🧠 Compute Layer
- Dynamically scaled via Kubernetes autoscaling or serverless functions
- Gateway handles routing; pods are short-lived and stateless
- Sandboxes (e.g., E2B) provide isolated, millisecond-start environments for safe tool execution
💾 Storage Layer — Tiered by Lifecycle & Access Pattern
| Tier | Data Type | Storage System | Purpose |
|---|---|---|---|
| Hot State | Loop step, plan, cursor position | Redis (KV store) | Low-latency checkpointing & crash recovery |
| Conversation Logs | Completed tasks & interactions | PostgreSQL (RDBMS) | Structured, auditable, relational history |
| Long-Term Memory | Summarized, vectorized memories | pgvector / Milvus (Vector DB) | Semantic search, recall, personalization |
| Artifacts & Assets | Uploaded files, outputs, tools, dynamic skills | S3 / OSS (Object Storage) | Durable, scalable, versionable binary storage |
⚠️ Key Challenge: Distributed data consistency across replicas — requires fine-grained locking, idempotent writes, and intelligent load-balancing strategies.
FastClaw: A Production-Ready Example
Workflow Summary:
- Two k8s pods host
fastclaw-gateway; requests route dynamically via LB - On request arrival:
- 2.1 Load prompts from DB (
soul.md,identity.md,user.md) - 2.2 Initialize ephemeral workspace dir in pod
- 2.3 Spin up sandbox with workspace mounted
- 2.4 Fetch user assets & system skills from object storage
- 2.5 Query memory via vector DB (
memory_search) - 2.6 Assemble full context → invoke LLM → parse tool calls
- 2.7 Execute tools inside sandbox, read/write workspace files
- 2.8 Save loop state as checkpoint in Redis (for resumability)
- 2.9 Return final artifacts to user
- Idle sandboxes auto-shutdown; workspace contents uploaded back to object storage
✅ Benefits:
– Horizontal scaling of gateways
– Elastic sandbox pool (fault-tolerant, low cold-start)
– Cost-efficient — no persistent pods
– IO bottleneck mitigated via tiered storage strategy
Real-World Migration: From OpenClaw to FastClaw
A production case study:
- Before (OpenClaw)
- 500 k8s pods, each capped at 4GB RAM
- 18 × 4c16g servers ($5k/month)
-
MRR: $8k/month → near-zero net margin
-
After (FastClaw)
- Reduced infrastructure to 3 servers
- Operational cost cut to 1/6
- Profitability achieved next month 😄
Why FastClaw Is Lighter:
- Codebase ≈ 1/40 size of OpenClaw
- Runtime memory footprint ≈ 1/7
- Single-binary distribution — zero environment dependencies
- Gateway startup: seconds (vs. 15s for OpenClaw)
FastClaw is built natively for cloud-native, multi-tenant agent hosting, yet fully compatible with local development and edge use cases.
Try It Today
Article originally published by “Aidoubi”.
Related Open-Source Projects
- OWL — Open-source universal agent with remote Ubuntu containers & GAIA-leading performance (57.7%)
- OpenManus — Local ReAct-style agent for browsing, coding, file ops
- AutoGPT & MetaGPT — Task automation & software company simulation agents
- GraphRAG, Dify, RAGFlow — RAG-focused frameworks with advanced indexing & orchestration
- LangGPT — Structured prompt engineering toolkit

